Archive for year: 2015
You are here: Home / 2015
https://axibase.com/wp-content/uploads/2015/12/block.png
602
630
Sergei Rodionov
/wp-content/uploads/2014/12/axibase_logo_orange-2.png
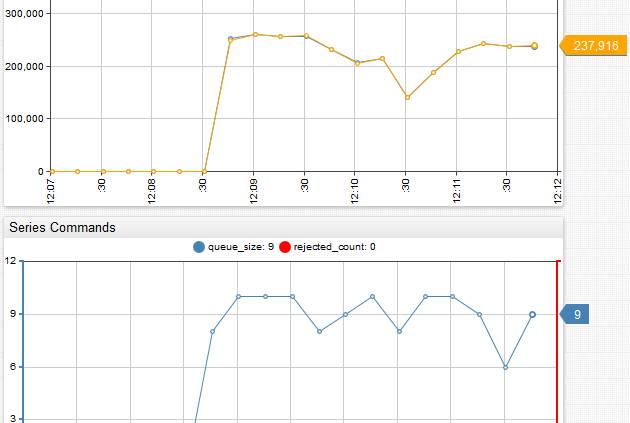
Sergei Rodionov2015-12-13 03:02:232016-11-10 09:32:16Data flow control in Time Series Databases