Data Flow Control in Time Series Database
Time series databases are designed to collect massive volumes of data at high frequency. With ingestion speeds reported at 100K to 1M inserts per second, TSDBs are substantially faster than relational databases and messaging middleware such as WebSphere MQ configured in message persistence mode.
However, regardless of how fast the ingestion rate is, it is important to make an upfront decision of how the database should operate if the amount of data received exceeds the amount of data committed to disk. This imbalance may occur due to a spike in data received or due to a drop in storage throughput.
The typical reasons for data storms include:
- Concurrent bulk import jobs are initiated
- Batch upload of large files is started
- Collectors resend locally buffered data after a network outage
- Collectors are misconfigured to send data at an abnormally high rate
Reasons for reduced storage throughput may include:
- Storage systems are overloaded with I/O-heavy Map/Reduce jobs
- Garbage collection pauses
- Network collisions, errors, outages
- Disk failures and subsequent RAID reconstructions
When the database is overflown with data and once local memory and file buffer limits are reached, there are two options to bring ingestion and storage rates in sync: slow down collectors or drop incoming data. There is also an option of running out of resources and terminating the database but lets not consider it as a viable alternative. We want the database to be continuously available, irrespective of the workloads.
The setting that controls the choice between slowing down producers and discarding data in the Axibase Time Series Database is called series.queue.rejection.policy and it accepts two options: BLOCK and DISCARD, with BLOCK being the default.
series.queue.rejection.policy = BLOCK
The BLOCK policy means that once a series queue reaches the limit specified with the series.queue.capacity setting, the database will stop receiving data from network commands, Data API insert requests, and file uploads. The database will not terminate connections – it will instead suspend reading data from sockets in blocking mode which will cause collectors to block as well. Each ingestion thread that is not able to add series to the persistence queue, which is full, will be blocked until there is space in the queue. This insures that no data is being lost while the database copes with a temporary imbalance.
The DISCARD policy means that once the queue limit is reached, newly received data will be dropped by the database to protect itself from memory or disk shortage. Ingestion threads will return instantly and the producers will not be subject to any blocking.
The differences between the two policies can be illustrated with metrics collected by ATSD:
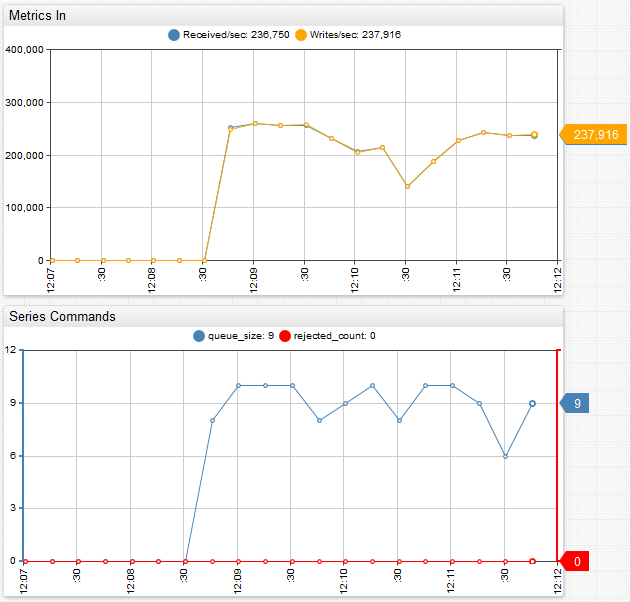
BLOCK policy:
Once the queue limit of 10 batches is reached, the database slows down producers and the received rate is bound by the write rate. Each batch is set to 2048 commands by default, setting the limit to a maximum of 20480 commands in memory. The queue size oscillates at or slightly below the limit while the producers are writing in blocking mode.
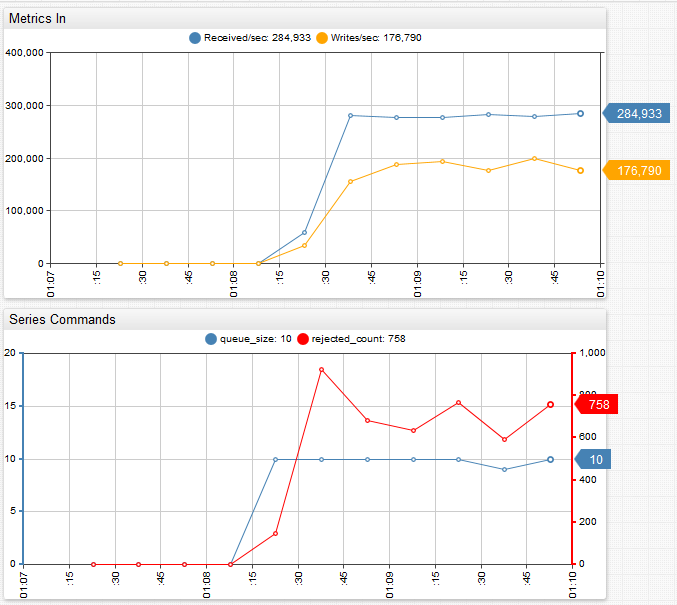
DISCARD policy:
The delta between received and written commands is large enough to quickly fill the queue up to its limit of 10 batches. Once the queue is full, the database starts dropping incremental commands and series rejected count shows an average of 800 batches dropped per 15 second interval. 800×2048/15 = 109000 commands dropped per second, which is approximately the difference between received and writes per second.
The trade-off between these policies is clear – what is good for producers is bad for data integrity. Should the BLOCK policy therefore be used everywhere? Not necessarily. There are situations where DISCARD makes for a reasonable design decision, including:
- Value of delayed data is low. Consider real-time alerting or automated trading systems. By the time queued data makes it into a database, it is of no use for real-time analytics because the metrics may have changed substantially since they were observed.
- Producers may fail if blocked. This applies to storage drivers where collection and transmission is done by the same thread. If the transmission code blocks, the storage driver will either stop collecting data or buffered samples will exhaust available memory.
Queue Size
To derive an optimal series queue size, first consider how much memory is available on the server and how much of it is allocated to ATSD java process (Xmx). Review the received rate as displayed on the ATSD default portal and run HBase Auto Tests to determine recommended thread pool and batch sizes.
series.batch.size = 1024 #number of series commands sent to disk in each transaction
series.queue.capacity = 32 #series queue limit, specified as number of batches
series.queue.pool.size = 4 #maximum number of concurrent storage workers
If Xmx exceeds 4GB, we recommend a queue limit of 256 and higher.
Metrics
The database exposes the following metrics that can be tracked to ensure data integrity:
series_pool_active_count #number of concurrent storage workers. Limited by 'series.queue.pool.size'
series_queue_size #number of series command batches in the queue. Limited by 'series.queue.capacity'
series_rejected_count #number of series command batches discarded during the 15 second interval because queue was full
metric_received_per_second #number of series commands received per second
metric_writes_per_second #number of series commands written to disk per second
Rule Engine
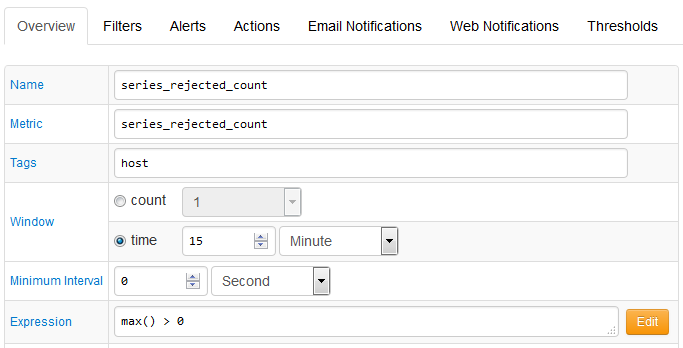
The metrics above can be used to create automated alerts. For example, the following rule sends an email alert if any series commands are rejected:
Portal
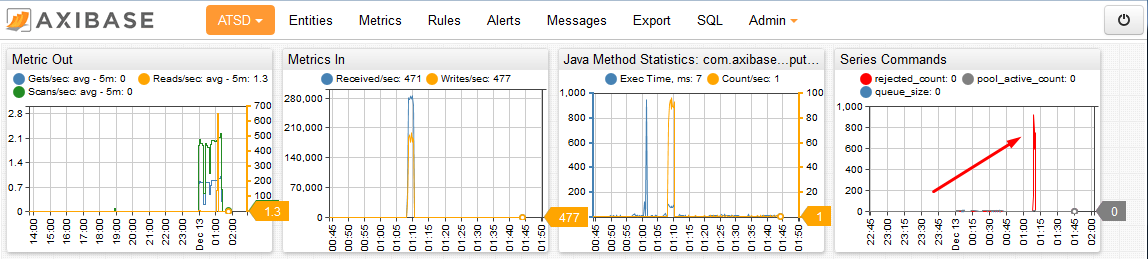
Reviewing the default ATSD portal to identify any occurrences of series rejections are equally important when determining optimal queue size.