Uploading CSV Files
Overview
Upload CSV files via REST API or manually through the web interface.

To process a CSV file, create a CSV parser. A parser splits the file into lines to create rows and then into tokens to create columns. Finally, the parser converts the newly created array of cells into series, property, and message commands.
Configuration Settings
| Setting | Description |
|---|---|
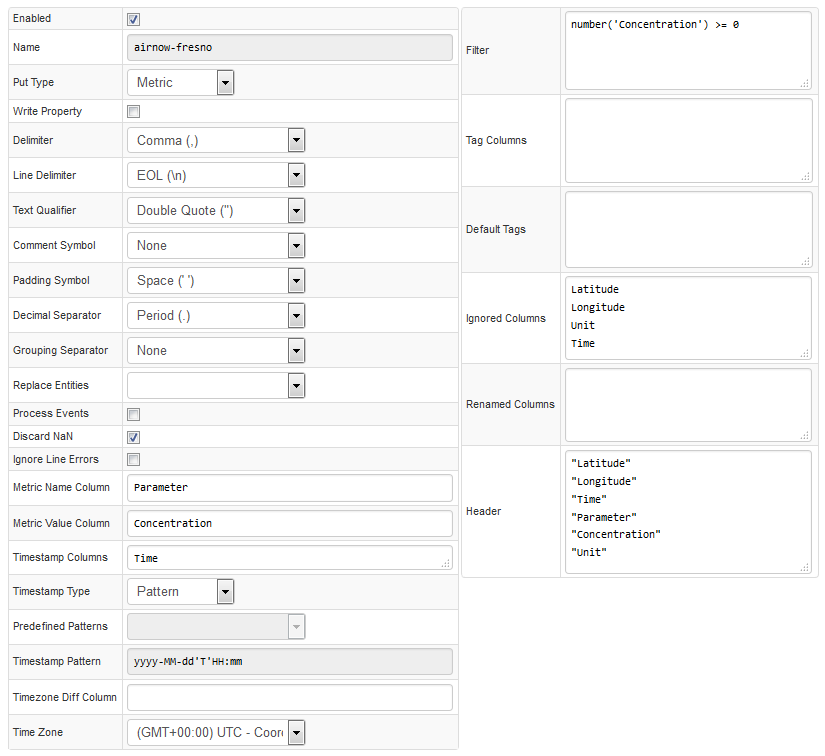
Enabled | Parser status. If parser is disabled, uploaded CSV files referencing this parser are discarded. |
Name | Unique parser name used as identifier when uploading files. |
Command Type | Type of data contained in the file: time series, properties, messages. |
Write Property | Enable writing data both as series and as properties. |
Entity Column | Name of column in CSV file containing the entities. For example: host or node. Multiple columns can be specified in the Entity Column field to concatenate their values into a composite entity name using a dash symbol – as a token.For example: Source CSV file: Year,Source,Destination,Travelers1995,Moscow,Berlin,2000000Entity Columns: Source,DestinationResulting Entity: Moscow-Berlin |
Entity Prefix | Prefix added to entity names. |
Default Entity | All data written to specific entity. |
Replace Entities | Replace entity names in the input file with their aliases from the selected Replacement Table |
Process Events | Process incoming data in the Rule Engine in addition to storing it in the database. |
Metric Prefix | Prefix added to metric names. |
Metric Name Column | Column containing metric names. |
Metric Value Column | Column containing metric values. |
Message Column | Column containing message text. |
Timestamp Columns | Columns containing the Timestamp for each data sample. In some cases, depending on the CSV file, the Timestamp can be split into multiple columns. For example: Date, Time. If there are two columns containing the Timestamp, then they are concatenated with a dash symbol (-) in the Timestamp Pattern field. For example: Source CSV File: Date,Time,Sensor,Power2015.05.15,09:15:00,sensor01,15Timestamp Columns: Date,TimeResult: Date-Time2015.05.15-09:15:00Timestamp Pattern Setting: yyyy.MM.dd-HH:mm:ss |
Timestamp Type | Pattern, Seconds (Unix time), Milliseconds (Unix time). |
Predefined Pattern | Predefined Timestamp formats. |
Timestamp Pattern | Custom timestamp format, specified manually. For example: dd-MMM-yy HH:mm:ssIf there are two columns containing the Timestamp, then in they are divided with a dash (-) in the pattern. |
Timezone Diff Column | Column containing the time difference calculated from UTC. |
Time Zone | Time zone for interpreting Timestamps. |
Filter | Expression applied to row. If expression returns false, the row is discarded.Filter syntax: Fields: timestamp – timestamp in milliseconds. Computed by parsing date from Time Column with specified Time Format and converted into milliseconds. row[ columnName] – text value of cell in the specific column.Functions: number( columnName) – returns numeric value of cell, or NaN (Not a Number) if the cell contains text which is not numeric.isNumber('columnName') – returns true if cell is a valid number.isBlank('columnName') – returns true is cell is empty string.upper( columnName) – converts cell text to uppercase.lower( columnName) – converts cell text to lowercase.date( endtime expression) – returns time in milliseconds.Filter examples: number( columnName) > 0isNumber('columnName')row[ columnName] LIKE 'abc*'upper( columnName) != 'INVALID'timestamp > date( current_day)timestamp > date( 2018-08-15T00:00:00Z)timestamp > date( now – 2 * year) |
Tag Columns | Columns converted to series tags. |
Default Tags | Predefined series tags, specified as name=value on multiple lines. |
Ignored Columns | List of columns ignored in METRIC and MESSAGE commands.These columns are retained in PROPERTY commands. |
Renamed Columns | List of column names to substitute input column headers, one mapping per line. Usage: inputname=storedname |
Header | Header to be used if the file contains no header or to replace existing header. |
Schema | Schema defines how to process cells based on their position. |
Columns contained in the CSV file that are not specified in any field in the parser are imported as metrics.
Parse Settings
| Setting | Description |
|---|---|
Delimiter | Separator dividing values: comma, semi-colon, or tab. |
Line Delimiter | End-of-line symbol: EOL (\n, \r\n) or semi-colon ; |
Text Qualifier | Escape character to differentiate separator as literal value. |
Comment Symbol | Lines starting with comment symbol such as hash # are ignored. |
Padding Symbol | Symbol appended to text values until all cells in the given column have the same width. Applies to fixed-length formats such as .dat format. |
Decimal Separator | Symbol used to mark the border between the integral and the fractional parts of a decimal numeral. Default: comma.Allowed values: period, comma. |
Grouping Separator | Symbol used to group thousands within the number. Default: none.Allowed values: none, period, comma, space. |
Fields Lengths | Width of columns in symbols. Padding symbols added to the end of the field to obey the fields lengths. For files in .dat format. |
Discard NaN | NaN (Not a Number) values are discarded |
Ignore Line Errors | If enabled, any errors while parsing the given line are ignored, including date parse errors, number parse errors, split errors, mismatch of rows, and header column counts. |
Ignore Header Lines | Ignore top-N lines from the file header |
Column-based Examples
Schema-based Parsing
In addition to column-based parsing described above, the database supports schema-based parsing using RFC 7111 selections:
select("#row=2-*").select("#col=3-*").
addSeries().
metric(cell(1, col)).
entity(cell(row, 2)).
tag(cell(1, 3),cell(row, 3)).
timestamp(cell(row, 1));
Produced series commands:
series e:nurswgvml007 d:2018-11-15T00:00:00Z m:space_used_%=72.2 t:disk=/dev/sda
series e:nurswgvml007 d:2018-11-15T00:00:00Z m:space_used_%=14.5 t:disk=/dev/sdb
series e:nurswgvml001 d:2018-11-15T00:00:00Z m:space_used_%=14.4 t:disk=/dev/sda1