ATSD Cluster Migration
These instructions describe how to upgrade an ATSD instance running on the Cloudera CDH cluster.
For non-distributed installations, refer to the following migration guide.
Versioning
| Code | ATSD Revision Number | Java Version | Cloudera Manager Version | CDH Version |
|---|---|---|---|---|
| Old | 16999 and earlier | 1.7 | 5.1 - 5.11 | 5.1 - 5.9 |
| New | 17000 and later | 1.8 | 5.12 | 5.10 |
Requirements
Disk Space
The migration procedure requires up to 30% of the current atsd_d table size to store new records before old data can be deleted.
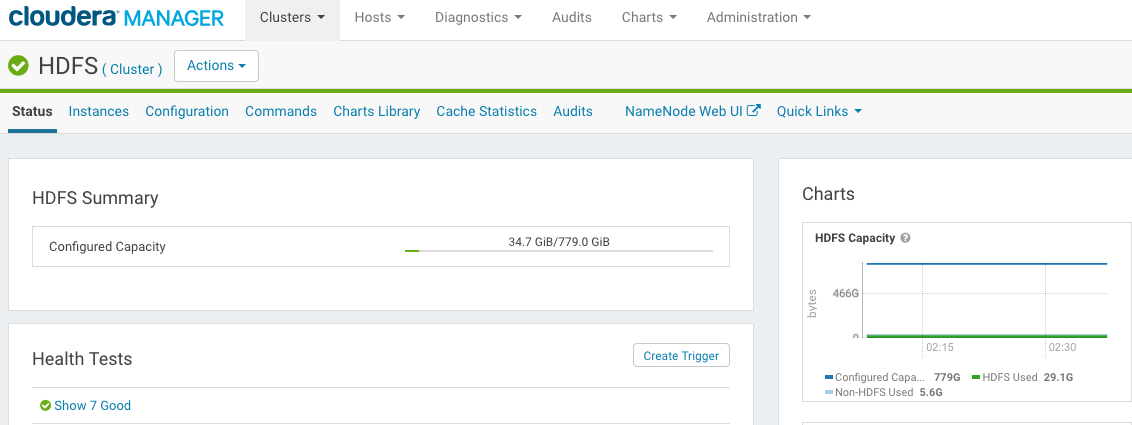
Open the Clusters > Cluster > HDFS > Status page in Cloudera Manager.
Be sure that enough configured capacity is available in HDFS.
Memory
The migration task is implemented as a Map-Reduce job and requires at least 4 GB of RAM available on each HBase region server.
Check Record Count for Testing
Log in to ATSD and open the SQL tab.
Count rows for one of the key metrics.
SELECT COUNT(*) FROM mymetric
The number must match the results after the migration.
Prepare ATSD For Upgrade
Stop ATSD.
/opt/atsd/atsd/bin/stop-atsd.sh
Take note of the table prefix specified in the /opt/atsd/atsd/conf/server.properties file.
cat /opt/atsd/atsd/conf/server.properties | grep "hbase.table.prefix" | cut -f 2 -d "="
This prefix is required in subsequent steps.
Install Java 8
Install Java 8 on the ATSD server.
Upgrade Cloudera Cluster
Upgrade Cloudera Manager to version 5.12.
Upgrade CDH to version 5.10.
Start HDFS, HBase, YARN and HistoryServer services.
Configure Migration Map-Reduce Job
Log in to the server where YARN ResourceManager is running.
Locate the yarn.keytab file.
sudo find / -name "yarn.keytab" | xargs ls -la | tail -n 1
-rw------- 1 yarn hadoop 448 Jul 29 16:44 /run/cloudera-scm-agent/process/7947-yarn-RESOURCEMANAGER/yarn.keytab
Switch to the yarn user.
sudo su yarn
Initiate a Kerberos session
Obtain the fully qualified hostname of the YARN ResourceManager server.
hostname -f
Authenticate with Kerberos using the located yarn.keytab file and the full hostname of the YARN ResourceManager.
kinit -k -t /run/cloudera-scm-agent/process/7947-yarn-RESOURCEMANAGER/yarn.keytab yarn/{yarn_rm_full_hostname}
Download the migration.jar file to the temporary /tmp/migration/ directory.
mkdir /tmp/migration
curl -o /tmp/migration/migration.jar \
https://axibase.com/public/atsd-125-migration/migration-hbase-1.2.0-cdh5.10.0.jar
Check that the current Java version is 8.
java -version
Add migration.jar, HBase configuration files, and HBase classes used by the migration job to Java and Hadoop classpaths.
export CLASSPATH=$CLASSPATH:$(hbase classpath):/tmp/migration/migration.jar
export HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/hbase/bin/../conf:$(hbase mapredcp):/tmp/migration/migration.jar
Modify Map-Reduce settings using parameters recommended by Axibase support based on the Data Reporter logs.
Run Migration Map-Reduce Job
Execute the below steps under the yarn user on the YARN ResourceManager server.
Backup atsd_d Table
Run the TableCloner task to rename atsd_d table as atsd_d_backup.
java com.axibase.migration.admin.TableCloner --table_name=atsd_d
If a custom table prefix is specified in the server.properties file, for example, if the prefix is set to atsd_custom_, change the table_name parameter accordingly:
java com.axibase.migration.admin.TableCloner --table_name=atsd_custom_d
Migrate Records
Launch the migration job with the nohup command.
The job creates a new data table, convert data from the backup table to the new format, and store the data in the new table.
The optional drop-annotations setting discards duplicate series annotations when copying the data.
Custom Table Prefix
nohup yarn com.axibase.migration.mapreduce.DataMigrator --forced \
--drop_annotations --source=atsd_custom_d_backup \
--destination=atsd_custom_d &> /tmp/migration/migration.log &
Default Table Prefix
nohup yarn com.axibase.migration.mapreduce.DataMigrator --forced \
--drop_annotations --source=atsd_d_backup \
--destination=atsd_d &> /tmp/migration/migration.log &
Monitoring Job Progress
The job takes several hours to complete.
Open Clusters > Cluster > YARN > Web UI > ResourceManager Web UI in Cloudera Manager.
Monitor the job progress.
tail -f /tmp/migration/migration.log
Note that the Yarn interface is stopped automatically once the job is finished.
Once the job is complete, the migration.log file contains the following message:
17/08/01 10:44:31 INFO mapreduce.DataMigrator: HFiles loaded, data table migration job completed, elapsed time: 45 minutes.
Deploy ATSD Coprocessors
Copy New Coprocessors into HDFS
Log in to HDFS NameNode server or another server with the DFS client.
Switch to the hdfs user.
sudo su hdfs
Copy atsd-hbase.17326.jar to the HDFS hbase.dynamic.jars.dir directory.
The path to this directory is set to ${hbase.rootdir}/lib by default in HBase.
hadoop fs -ls /hbase/lib/ # check existence
hadoop fs -mkdir /hbase/lib/ # if not exists
curl -O https://axibase.com/public/atsd-125-migration/atsd-hbase.17326.jar
hadoop fs -put -f atsd-hbase.17326.jar /hbase/lib/atsd-hbase.jar
hadoop fs -ls /hbase/lib
Found 1 items
-rw-r--r-- 3 hdfs hbase 547320 2017-08-23 13:03 /hbase/lib/atsd-hbase.jar
This path must match the coprocessors.jar setting specified in the /opt/atsd/atsd/conf/server.properties file in the ATSD server as outlined below.
Remove Old Coprocessors
ATSD coprocessors added to HBase CoprocessorRegion Classes have been loaded automatically and therefore must be removed from HBase settings in Cloudera Manager.
Remove old jar files from the local file system on each HBase Region Server.
Remove Coprocessor Settings
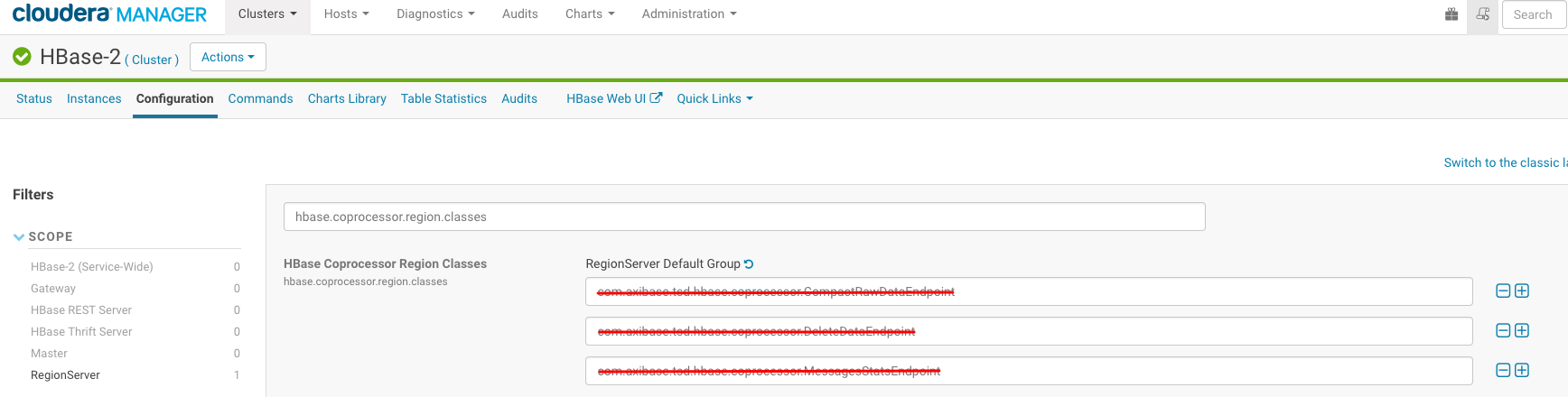
Open the Clusters > Cluster > HBase-2 tab in Cloudera Manager.
Open the Configuration tab.
Search for the hbase.coprocessor.region.classes setting.
Remove all ATSD coprocessors and save settings:
Remove Coprocessor jar Files
Find ATSD coprocessors jar files on each Region Server:
sudo find /opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/ -name "atsd*.jar"
Remove files found by the above search.
Restart HBase.
Configure ATSD
Log in to the ATSD Server.
Switch to the axibase user.
sudo su axibase
Remove deprecated settings.
sed -i '/^hbase.regionserver.lease.period/d' /opt/atsd/atsd/conf/hadoop.properties
Add path to co-processor jar file.
echo "coprocessors.jar=hdfs:///hbase/lib/atsd-hbase.jar" >> /opt/atsd/atsd/conf/server.properties
Upgrade jar files and start-up scripts.
rm -f /opt/atsd/atsd/bin/*
curl -o /opt/atsd/atsd/bin/atsd.17370.jar https://axibase.com/public/atsd-125-migration/atsd.17370.jar
curl -o /opt/atsd/scripts.tar.gz https://axibase.com/public/atsd-125-migration/scripts.tar.gz
tar -xf /opt/atsd/scripts.tar.gz -C /opt/atsd/ atsd
rm /opt/atsd/scripts.tar.gz
rm -rf /opt/atsd/hbase
rm -rf /opt/atsd/collectors
Update JAVA_HOME in the start-atsd.sh file:
jp=`dirname "$(dirname "$(readlink -f "$(which javac || which java)")")"`; sed -i "s,^export JAVA_HOME=.*,export JAVA_HOME=$jp,g" /opt/atsd/atsd/bin/start-atsd.sh
Edit the /opt/atsd/atsd/conf/atsd-env.sh file.
Increase Xmx memory to 50% of available RAM memory on the ATSD server:
JAVA_OPTS="-server -Xmx4096M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath="$atsd_home"/logs"
Start ATSD.
/opt/atsd/atsd/bin/start-atsd.sh
Review the start log for any errors:
tail -f /opt/atsd/atsd/logs/atsd.log
Watch for ATSD start completed message at the end of the start.log.
Web interface is now accessible on port 8443 (HTTPS).
Check Migration Results
Open the SQL tab in ATSD.
Count rows for the previously selected metric and compare the results.
SELECT COUNT(*) FROM mymetric
The number of records must match the results prior to migration.
Delete Backup Table
Log in to HBase shell.
Delete atsd_d_backup table. Adjust the table name if a custom prefix is specified in the server.properties file.
/usr/lib/hbase/bin/hbase shell
hbase(main):001:0> disable 'atsd_d_backup'
hbase(main):002:0> drop 'atsd_d_backup'
hbase(main):003:0> exit
Delete Temporary Migration Folder
rm -rf /tmp/migration