SQL
ATSD supports SQL for retrieving, inserting, and deleting time series data stored in the database.
SQL statements can be executed via the web-based console, on schedule, or using the JDBC and ODBC drivers.
- Syntax
- Processing Sequence
- Grouping
- Date Aggregation
- Interpolation
- Regularization
- Partitioning
- Ordering
- Limiting
- Inline Views
- Joins
- Options
- Permissions
- API Endpoint
- Scheduled Reports
- Query Optimization
- SQL Compatibility
- Examples
Syntax
The SQL statement begins with one of the following keywords: SELECT, INSERT, UPDATE, DELETE and can end with a semi-colon character.
SELECT Syntax
The SELECT statement consists of a SELECT expression, a FROM query, a WHERE clause, and other clauses for filtering, grouping, and ordering the results.
SELECT { * | { expr [ .* | [ AS ] alias ] } }
FROM "<table-name>" [[ AS ] alias ]
[ { INNER | [ FULL ] OUTER } JOIN [ USING ENTITY ] "<table-name>" [[ AS ] alias ] [ ON joinExpr ] ]
[ WHERE booleanExpr ]
[ WITH withExpr ]
[ GROUP BY expr [, ...] ]
[ HAVING booleanExpr ]
[ WITH withExpr ]
[ ORDER BY expr [{ ASC | DESC }] [, ...] ]
[ LIMIT count [ OFFSET skip ]]
[ OPTION(expr) [...]]
Example:
SELECT datetime, entity, value*2 -- SELECT expression
FROM "mpstat.cpu_busy" -- table (metric)
WHERE datetime >= '2017-06-15T00:00:00Z' -- WHERE clause
LIMIT 1 -- other clauses
INSERT Syntax
INSERT INTO "<table-name>" (column_1 [, column_N])
VALUES (expr_1 [, expr_N])
The column name can be one of the pre-defined series columns, for example: datetime, entity, value, tags.<name>.
The time and datetime column values can be specified as a literal date or a calendar expression.
Example:
INSERT INTO "df.disk_used" (entity, datetime, value, tags.mount_point, tags.file_system)
VALUES ('nurswgvml007', '2019-02-01 00:00:05', 99.83, '/app', '/dev/sdb1')
INSERT INTO "mpstat.cpu_busy" (entity, datetime, value)
VALUES ('nurswgvml007', now, 0.10)
To insert values for multiple metrics, use the built-in atsd_series table in which case metric names are extracted from numeric columns:
INSERT INTO atsd_series (metric_1 [, metric_N], column_1 [, column_N])
VALUES ('<metric_1_value>' [, '<metric_2_value>'], expr_1 [, expr_N])
Example:
INSERT INTO atsd_series ("mpstat.cpu_busy", "mpstat.cpu_user", entity, datetime)
VALUES (0.10, 0.02, 'nurswgvml007', now)
UPDATE Syntax
UPDATE "<table-name>" SET column_1 = expr_1 [, column_N = expr_N]
The column name can be one of the pre-defined series columns, for example: datetime, entity, value, tags.<name>.
The time and datetime column values can be specified as a literal date or a calendar expression.
If the previous value is not found, a new value is inserted with the specified timestamp.
Example:
UPDATE "df.disk_used" SET entity = 'nurswgvml007',
datetime = '2019-02-01 00:00:05', value = 99.83,
tags.mount_point = '/app', tags.file_system = '/dev/sdb1'
UPDATE "mpstat.cpu_busy" SET entity = 'nurswgvml007', datetime = now, value = 0.10
DELETE Syntax
DELETE FROM table
WHERE booleanExpr
Example:
DELETE FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2017-06-15T00:00:00Z' AND '2017-06-16T00:00:00Z' EXCL
SELECT Processing Sequence
- FROM retrieves rows from virtual tables.
- JOIN merges rows from different tables.
- WHERE filters rows.
- GROUP BY assigns rows to groups.
- HAVING filters groups.
- SELECT chooses columns or creates new columns to include in each row.
- ORDER BY sorts rows by value of its columns.
- LIMIT selects a subset of rows.
SELECT Expression
The SELECT expression contains one or multiple columns and expressions applied to the query results.
SELECT column1, UPPER(column2), 100 * column3
FROM ...
Tables
Virtual Tables
The FROM query can reference virtual tables that correspond to metric names. The list of metrics is displayed on the Metrics tab in the main menu.
A virtual table represents a subset of records for the given metric stored by the database in the shared physical table.
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
WHERE datetime >= '2017-06-15T00:00:00Z'
In the example above, the "mpstat.cpu_busy" table contains records for the mpstat.cpu_busy metric.
atsd_series Table
As an alternative to specifying metric names as tables, the FROM query can refer to the pre-defined atsd_series table and include metric names in the WHERE clause instead.
SELECT entity, metric, datetime, value
FROM atsd_series
WHERE metric = 'mpstat.cpu_busy'
-- WHERE metric IN ('mpstat.cpu_busy', 'mpstat.cpu_user')
-- WHERE metric LIKE 'mpstat.cpu%'
-- WHERE metric IN metrics('nurswgvml007')
-- WHERE metric IN metrics('entity-1', 'entity-2')
AND entity = 'nurswgvml007'
AND datetime >= '2017-06-15T00:00:00Z'
Note
LIKE operator is case-sensitive.
Note
The number of metrics retrieved with the metric LIKE (expr) condition is subject to a limit set by the sql.metric.like.limit setting. The default limit is 50.
atsd_entity Table
The atsd_entity is a metadata table which provides access to the list of entities and their fields.
SELECT name, label, date_format(creationTime)
FROM atsd_entity
WHERE creationTime > now - 1*week
ORDER BY creationTime DESC
LIMIT 10
| name | label | date_format(creationTime) |
|------------|--------------------------|---------------------------|
| 412366f9d | JENKINS_AxibaseAPI | 2018-10-24T14:53:34Z |
| dfbbbf412 | atsd_package_validation | 2018-10-24T14:46:09Z |
The atsd_entity table can be used to retrieve both the list of entities as well as unique entity tags.
SELECT tags."site" AS Site
FROM atsd_entity
WHERE tags."site" != ''
GROUP BY tags."site"
atsd_metric Table
The atsd_metric is a metadata table which provides access to the list of metrics and their fields.
SELECT name, label, date_format(creationTime)
FROM atsd_metric
WHERE label IS NOT NULL
ORDER BY creationTime DESC
LIMIT 10
| name | label | date_format(creationTime) |
|-----------|------------------|---------------------------|
| cpu_busy | CPU Busy, % | 2018-07-05T15:18:00Z |
| membuf | Memory Buffered | 2018-02-12T12:36:54Z |
The list of metrics can be filtered by name or fields, as well as using the metrics() function to retrieve metrics collected by the specified entity or multiple entities.
SELECT name, label, date_format(lastInsertTime)
FROM atsd_metric
WHERE name IN metrics('entity-1', 'entity-2')
ORDER BY name
WHERE Clause
The WHERE clause is a condition which must be satisfied by the row to be included in results.
Columns referenced in the WHERE clause are replaced by their value for the given row. The condition is then evaluated for each row, and if the result is true, the row is included in the result set.
Typically, the WHERE clause includes an interval condition to retrieve data for the specified time range.
The clause can be built from multiple conditions, each comparing values using operators:
- Numeric operators:
<, >, <=, >=, =, <>, !=. - String operators:
<, >, <=, >=, =, <>, !=, LIKE, REGEX, IS.
The operators
!=and<>cannot be applied to columnstimeanddatetime. The operators<, >, <=, >=applied to string values, such as series/entity/metric tag values, perform lexicographical comparisons.
The result of evaluating a condition is a boolean value. Multiple conditions can be combined using the logical operators AND, OR, and NOT.
SELECT entity, datetime, value, tags.*
FROM "df.disk_used"
WHERE datetime >= '2017-06-15T00:00:00Z'
AND (entity IN ('nurswgvml007', 'nurswgvml010')
OR tags.file_system LIKE '/dev/%'
OR value/1024 > 100000)
Operator Precedence
-(unary minus)*,/,%(modulo)+,-(binary minus)=,<>,>=,>,<=,<,!=,IS,LIKE,REGEX,INBETWEEN,CASE,WHEN,THEN,ELSENOTANDOR
Operators with the same precedence level within an expression are processed from left to right.
Truth Tables for Logical Operators
| X | NOT X |
|---|---|
true | false |
false | true |
NULL | NULL |
| X | Y | X AND Y | X OR Y |
|---|---|---|---|
true | true | true | true |
true | false | false | true |
false | false | false | false |
true | NULL | NULL | true |
false | NULL | false | NULL |
NULL | NULL | NULL | NULL |
Other Clauses
- JOIN
- GROUP BY
- HAVING
- ORDER BY
- LIMIT, OFFSET
Functions
- ROW_NUMBER returns the row index within each partition.
- INTERPOLATE fills the gaps in an irregular series.
- INTERVAL_NUMBER returns the interval index when multiple intervals are selected with Interval Condition.
- LAST_TIME returns last insert time in milliseconds for each series.
Data Types
| Type Name | Type Alias |
|---|---|
| BOOLEAN | - |
| DECIMAL | - |
| DOUBLE | - |
| FLOAT | - |
| INTEGER | INT |
| BIGINT | LONG |
| SMALLINT | SHORT |
| VARCHAR | STRING |
| TIMESTAMP | - |
| JAVA_OBJECT | - |
The data type returned by the database for a given value column depends on the data type of the metric.
The NUMBER (parent type for all numeric data types) and STRING type can be used to convert data types with the CAST function.
The BOOLEAN type is produced by including boolean comparisons in the SELECT expression.
SELECT datetime, value, value > 0 AS Is_Positive
FROM "mpstat.cpu_busy"
LIMIT 1
| datetime | value | Is_Positive |
|----------------------|-------|-------------|
| 2017-04-17T07:29:04Z | 0 | false |
Comments
Comments can be inserted into SQL statements with -- (two hyphens) and /* */ (multi-line) to provide descriptive information about the query and its expected results.
-- comment single-line text
/*
comment text on
multiple lines
*/
Comments are not allowed after the statement termination character ;.
Columns
Predefined Columns
Virtual tables have the same pre-defined columns since the underlying data is physically stored in a single partitioned table.
Series Columns
| Name | Type | Description |
|---|---|---|
metric | varchar | Metric name, same as virtual table name. |
entity | varchar | Entity name. |
value | number | Series numeric value. |
text | varchar | Series text value. |
tags.{name} | varchar | Series tag value. Returns NULL if the specified tag does not exist for this series. |
tags | varchar | All series tags, concatenated to name1=value;name2=value format. |
tags.* | varchar | Expands to multiple columns, each column containing a separate series tag. Tag columns, if present, are sorted by name. |
datetime | timestamp | Sample time in ISO format, for example 2017-06-10T14:00:15.020Z.In GROUP BY PERIOD queries, the datetime column returns the period start time in ISO format, same as date_format(PERIOD(...)). |
time | bigint | Sample time Unix time with millisecond precision, for example 1408007200000.In GROUP BY PERIOD queries, the time column returns the period start time. |
Metric Columns
| Name | Type | Description |
|---|---|---|
metric.name | varchar | Metric name. |
metric.label | varchar | Metric label. |
metric.description | varchar | Metric description. |
metric.timeZone | varchar | Metric time zone. |
metric.interpolate | varchar | Metric interpolation setting. |
metric.tags.{name} | varchar | Metric tag value. Returns NULL if the specified tag does not exist for this metric. |
metric.tags | varchar | All metric tags, concatenated to name1=value;name2=value format. |
metric.tags.* | - | Expands to multiple columns, each column containing a separate metric tag. Tag columns, if present, are sorted by name. |
metric.dataType | varchar | Data Type. |
metric.enabled | boolean | Enabled status. Incoming data is discarded for disabled metrics. |
metric.persistent | boolean | Persistence status. Non-persistent metrics are not stored in the database and are only processed by the rule engine. |
metric.filter | varchar | Persistence filter expression. Discards series that do not match this filter. |
metric.creationTime | bigint | Metric creation time as Unix time with millisecond precision. |
metric.lastInsertTime | bigint | Last time a value is received for this metric by any series, measured as Unix time with millisecond precision. |
metric.retentionIntervalDays | integer | Number of days to retain values for this metric in the database. |
metric.versioning | boolean | If set to true, enables versioning for the specified metric. When metrics are versioned, the database retains the history of series value changes for the same timestamp along with version_source and version_status. |
metric.minValue | double | Minimum value for Invalid Action trigger. |
metric.maxValue | double | Maximum value for Invalid Action trigger. |
metric.invalidValueAction | varchar | Invalid Action type. |
metric.units | varchar | Measurement units. |
metric.* | - | Expands to multiple columns for each metric field, as well as the metric.tags column. |
Entity Columns
| Name | Type | Description |
|---|---|---|
entity.label | varchar | Entity label. |
entity.timeZone | varchar | Entity time zone. |
entity.interpolate | varchar | Entity interpolation setting. |
entity.tags.{name} | varchar | Entity tag value. Returns NULL if the specified tag does not exist for this entity. |
entity.tags | varchar | All entity tags, concatenated to name1=value;name2=value format. |
entity.tags.* | - | Expands to multiple columns, each column containing a separate entity tag. Tag columns, if present, are sorted by name. |
entity.groups | varchar | List of entity groups, to which the entity belongs, separated by semi-colon ;. |
entity.enabled | boolean | Enabled status. Incoming data is discarded for disabled entity. |
entity.creationTime | bigint | Entity creation time as Unix time with millisecond precision. |
entity.* | - | Expands to multiple columns for each entity field, as well as the entity.tags column. |
New columns can be created by applying functions and arithmetic expressions to existing columns. The computed columns can be included both in the SELECT expression, as well as in the WHERE, HAVING, and ORDER BY clauses.
SELECT t1.datetime, t1.entity, t1.value + t2.value AS cpu_sysusr
FROM "mpstat.cpu_system" t1
JOIN "mpstat.cpu_user" t2
WHERE t1.datetime >= '2017-06-15T00:00:00Z'
AND cpu_sysusr > 10
The list of all predefined columns can be requested with the SELECT * syntax, except for queries with the GROUP BY aggregation clause.
SELECT * FROM "mpstat.cpu_busy" WHERE datetime > current_minute LIMIT 1
| time | datetime | value | text | metric | entity | tags |
|---------------|----------------------|-------|------|----------|--------------|------|
| 1499177532000 | 2017-07-04T14:12:12Z | 5 | null | cpu_busy | nurswgvml007 | null |
JOIN queries with an asterisk return columns for all tables referenced in the query.
SELECT *
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime BETWEEN '2017-06-16T13:00:00Z' AND '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
| t1.time | t1.datetime | t1.value | t1.text | t1.metric | t1.entity | t1.tags | t2.time | t2.datetime | t2.value | t2.text | t2.metric | t2.entity | t2.tags |
|---------------|----------------------|-------------------|---------|-----------|--------------|---------|---------------|----------------------|----------|---------|-----------|--------------|---------|
| 1497618006000 | 2017-06-16T13:00:06Z | 5.050000190734863 | null | cpu_busy | nurswgvml006 | null | 1497618006000 | 2017-06-16T13:00:06Z | 78328 | null | memfree | nurswgvml006 | null |
| null | null | null | null | null | null | null | 1497618021000 | 2017-06-16T13:00:21Z | 76980 | null | memfree | nurswgvml006 | null |
In the case of a JOIN query, the SELECT * syntax can be applied to each table separately.
SELECT t1.datetime, t1.value, t2.*
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime BETWEEN '2017-06-16T13:00:00Z' AND '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
| t1.datetime | t1.value | t2.time | t2.datetime | t2.value | t2.text | t2.metric | t2.entity | t2.tags |
|----------------------|-------------------|---------------|----------------------|----------|---------|-----------|--------------|---------|
| 2017-06-16T13:00:06Z | 5.050000190734863 | 1497618006000 | 2017-06-16T13:00:06Z | 78328 | null | memfree | nurswgvml006 | null |
| null | null | 1497618021000 | 2017-06-16T13:00:21Z | 76980 | null | memfree | nurswgvml006 | null |
The time and datetime columns contain the same value (record time) in different data types and can be used interchangeably, for instance in the GROUP BY clause and the SELECT expression.
SELECT datetime, entity, count(*) -- 'time' column in SELECT
FROM "df.disk_used"
-- By default BETWEEN is inclusive of upper range. Use BETWEEN a AND b EXCL to override.
WHERE datetime BETWEEN '2017-06-15' AND '2017-06-15' -- 'datetime' column in WHERE
GROUP BY time, entity -- 'time' column in GROUP BY
The SELECT expression in JOIN queries can include both fully qualified column names such as {table}.datetime and short names datetime and time containing row timestamp calculated as COALESCE(t1.datetime, t2.datetime, ...).
SELECT datetime, t1.datetime, t2.datetime
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime BETWEEN '2017-06-15T13:00:00Z' AND '2017-06-15T13:10:00Z'
AND t1.entity = 'nurswgvml006'
| datetime | t1.datetime | t2.datetime |
|----------------------|----------------------|----------------------|
| 2017-06-15T13:00:01Z | 2017-06-15T13:00:01Z | null |
| 2017-06-15T13:00:12Z | null | 2017-06-15T13:00:12Z |
| 2017-06-15T13:00:17Z | 2017-06-15T13:00:17Z | null |
Series Value Columns
Each series sample contains:
- Numeric value, accessible with the
valuecolumn. - String value, accessible with the
textcolumn.
The text value can be inserted with series command and the series insert method in Data API.
series d:2017-10-13T08:00:00Z e:sensor-1 m:temperature=20.3
series d:2017-10-13T08:15:00Z e:sensor-1 m:temperature=24.4 x:temperature="Provisional"
series d:2017-10-13T10:30:00Z e:sensor-1 x:status="Shutdown by adm-user, RFC-5434"
SELECT entity, metric, datetime, value, text
FROM atsd_series
WHERE metric IN ('temperature', 'status')
AND datetime >= '2017-06-15T08:00:00Z'
| entity | metric | datetime | value | text |
|----------|-------------|----------------------|-------|--------------------------------|
| sensor-1 | temperature | 2017-06-15T08:00:00Z | 20.3 | null |
| sensor-1 | temperature | 2017-06-15T08:15:00Z | 24.4 | Provisional |
| sensor-1 | status | 2017-06-15T10:30:00Z | NaN | Shutdown by adm-user, RFC-5434 |
Numeric Precedence
If the value column in an atsd_series query returns numbers for metrics with different data types, the prevailing data type is determined based on the following rules:
- If all data types are integers (
short,integer,bigint), the prevailing integer type is returned. - If all data types are decimals (
float,double,decimal), the prevailing decimal type is returned. - If the data types contain both integers and decimals, the
decimaltype is returned.
Series Tag Columns
To include tags in the SELECT expression, specify tags.*, tags, or tags.{tag-name} as the column name.
Specific tags can be accessed by name such as tags.{tag-name}. When specified in the SELECT expression, tags.* creates a column for each element in the collection. The columns are ordered by name.
If the property is not present, the tags.{tag-name} expression returns NULL.
SELECT datetime, entity, value, tags.*, tags, tags.mount_point, tags.file_system
FROM "df.disk_used"
WHERE entity = 'nurswgvml010'
AND datetime >= '2017-06-15T00:00:00Z'
ORDER BY datetime
| datetime | entity | value | tags.file_system | tags.mount_point | tags | tags.mount_point | tags.file_system |
|----------------------|--------------|---------------|------------------|------------------|----------------------------------------|------------------|------------------|
| 2017-06-15T00:00:09Z | nurswgvml010 | 8348272.0000 | /dev/sda1 | / | file_system=/dev/sda1;mount_point=/ | / | /dev/sda1 |
| 2017-06-15T00:00:09Z | nurswgvml010 | 31899136.0000 | /dev/sdb1 | /app | file_system=/dev/sdb1;mount_point=/app | /app | /dev/sdb1 |
To filter records with or without specified series tags, use the IS NOT NULL or IS NULL operators.
The tags and tags.{tag-name} syntaxes can also be used in WHERE, ORDER, GROUP BY and other clauses.
SELECT entity, count(value), tags.*
FROM "df.disk_used"
WHERE datetime >= NOW - 5*MINUTE
AND entity = 'nurswgvml010'
AND tags.mount_point = '/'
GROUP BY entity, tags
| entity | count(value) | tags.mount_point | tags.file_system |
|--------------|--------------|------------------|------------------|
| nurswgvml010 | 20 | / | /dev/sda1 |
Entity Tag Columns
Entity tag values can be included in a SELECT expression by specifying entity.tags.{tag-name} or {entity.tags} as the column name.
entity.tags is a map object whose properties can be accessed with the {tag-name} key.
If there is no record for the specified key, the entity.tags.{tag-name} expression returns NULL.
SELECT entity, entity.tags.os, entity.tags.app, AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
GROUP BY entity
| entity | entity.tags.os | entity.tags.app | AVG(value) |
|--------------|----------------|-----------------------|------------|
| nurswgvml006 | Linux | Hadoop/HBase | 29.9 |
| nurswgvml007 | Linux | ATSD | 32.4 |
| nurswgvml009 | null | Oracle EM | 35.9 |
| nurswgvml010 | Linux | SVN, Jenkins, Redmine | 6.4 |
| nurswgvml011 | Linux | HMC Simulator, mysql | 5.6 |
| nurswgvml102 | Linux | Router | 1.5 |
| nurswgvml502 | null | null | 16.3 |
To filter records with or without a specified entity tag, use the IS NOT NULL or IS NULL operators:
SELECT entity, entity.tags.os, entity.tags.app, AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
AND entity.tags.os IS NULL
GROUP BY entity
| entity | entity.tags.os | entity.tags.app | AVG(value) |
|--------------|----------------|-----------------|------------|
| nurswgvml009 | null | Oracle EM | 37.2 |
| nurswgvml502 | null | null | 15.4 |
Metric Tag Columns
Metric tag values can be included in SELECT expressions by specifying metric.tags.*, metric.tags, or metric.tags.{tag-name} as the column name.
To refer to a specific metric tag, use the metric.tags.{tag-name} syntax.
If there is no value for the specified tag, the metric.tags.{tag-name} expression returns NULL.
The expression metric.tags.* expands to multiple columns which are sorted by name.
Metric tag columns are supported only in a SELECT expression.
SELECT entity, AVG(value), metric.tags.*, metric.tags, metric.tags.table
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
GROUP BY entity
| entity | AVG(value) | metric.tags.source | metric.tags.table | metric.tags | metric.tags.table |
|--------------|------------|--------------------|-------------------|----------------------------|-------------------|
| nurswgvml006 | 13.1 | iostat | System | source=iostat;table=System | System |
| nurswgvml007 | 10.8 | iostat | System | source=iostat;table=System | System |
| nurswgvml009 | 21.2 | iostat | System | source=iostat;table=System | System |
Entity Group Column
An entity.groups column contains a list of entity groups to which the entity belongs.
The column can be specified in the SELECT expression to print out the ordered list of entity group names, separated by semi-colon.
SELECT datetime, entity, value, entity.groups
FROM "mpstat.cpu_busy"
WHERE entity LIKE 'nurswgvml00%'
AND datetime >= CURRENT_HOUR
ORDER BY datetime
Note
LIKE operator is case-sensitive.
| datetime | entity | value | entity.groups |
|----------------------|--------------|-------|------------------------------------------|
| 2017-06-15T15:00:06Z | nurswgvml009 | 3.0 | nur-collectors;nmon-linux |
| 2017-06-15T15:00:07Z | nurswgvml007 | 44.7 | java-loggers;nur-collectors;nmon-linux |
| 2017-06-15T15:00:16Z | nurswgvml006 | 4.0 | nur-collectors;nmon-linux;nmon-sub-group |
The entity.groups column can be referenced in the WHERE clause to filter results based on group membership.
Supported syntax:
entity.groups IN ('group-1', 'group-2') -- entity belongs to one of the groups listed in the IN clause
entity.groups NOT IN ('group-1', 'group-1') -- entity does NOT belong to any of the groups listed in the IN clause
'group-1' IN entity.groups -- entity belongs to the specified group
'group-1' NOT IN entity.groups -- entity does NOT belong to the specified group
Entity group names are case-sensitive.
SELECT datetime, entity, value, entity.groups
FROM "mpstat.cpu_busy"
WHERE 'java-loggers' IN entity.groups
AND datetime >= CURRENT_HOUR
ORDER BY datetime
| datetime | entity | value | entity.groups |
|----------------------|--------------|-------|------------------------------------------|
| 2017-06-15T15:00:07Z | nurswgvml007 | 44.7 | java-loggers;nur-collectors;nmon-linux |
| 2017-06-15T15:00:21Z | nurswgvml102 | 4.0 | java-loggers;network-rtr |
To check that a string expression matches one of the entity names in the specified group, use the is_entity_in_group() function.
SELECT entity, AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime > current_hour
AND is_entity_in_group(REPLACE(entity, 'nur', ''), 'nur-hbase')
GROUP BY entity
Group By Columns
In a GROUP BY query, datetime and PERIOD() columns return the same value (the period start time) in ISO format. In this case, date_format(PERIOD(5 MINUTE)) can be replaced with datetime in the SELECT expression.
SELECT entity, datetime, date_format(PERIOD(5 MINUTE)), AVG(value)
FROM "mpstat.cpu_busy"
WHERE time >= CURRENT_HOUR AND time < NEXT_HOUR
GROUP BY entity, PERIOD(5 MINUTE)
Columns referenced in the SELECT expression must be included in the GROUP BY clause.
Identifiers
Use double quotation marks to enquote a table name, column name, tag name or an alias if it contains a reserved column name, a keyword, a function name, or a special character including space, ., +, -, *, /, ,, ", '.
-- Special character
SELECT entity.tags."file-system" FROM "disk.io" WHERE tags."disk.name"
-- Reserved column name
SELECT value*5 AS "value"
-- SQL identifier
SELECT tags.action AS "select"
-- Function name: avg
SELECT * FROM "avg"
Double quotes in identifiers can be escaped by doubling the quote symbol.
-- column alias: The "main" entity
SELECT entity AS "The ""main"" entity"
-- series tag: hello"world
SELECT tags."hello""world"
Aliases
Table and column aliases can be unquoted or enclosed in double quotation marks.
Unquoted alias must begin with letter [a-zA-Z], followed by a letter, digit or underscore.
The AS keyword is optional.
SELECT tbl.value*100 AS "cpu_percent", tbl.datetime "sample-date"
FROM "mpstat.cpu_busy" tbl
WHERE datetime >= NOW - 1*MINUTE
ORDER BY "sample-date"
For aliased columns, the underlying column and table names, or expression text, are included in table schema section of the metadata.
"tableSchema": {
"columns": [{
"columnIndex": 1,
"name": "cpu_percent",
"titles": "tbl.value*100",
"datatype": "float",
"table": "tbl"
}, {
"columnIndex": 2,
"name": "sample-date",
"titles": "datetime",
"datatype": "xsd:dateTimeStamp",
"table": "tbl",
"propertyUrl": "atsd:datetime",
"dc:description": "Sample time in ISO8601 format"
}]
}
Reserved Words
AND AS ASC AUTO BETWEEN BY CALENDAR CASE CAST CURRENT DAYOFMONTH
DAYOFWEEK DAYOFYEAR DBTIMEZONE DELETE DENSE_RANK DESC DETAIL
DISTINCT ELSE END ENDTIME END_TIME ENTITY ESCAPE EXCL EXTEND
FALSE FIRST_VALUE_TIME FLOAT FROM FULL GROUP GROUPS HAVING IN
INCL INNER INTEGER INTERPOLATE IS ISNULL JOIN LAG LAST_TIME
LEAD LIKE LIMIT LINEAR LOOKUP MAPDB METRIC NAN NEXT NO NONE
NOT NULL NUMBER OFFSET ON OPTION OR ORDER OUTER PERIOD POPULATION
PRECEDING PREVIOUS RANK REGEX ROW ROW_MEMORY_THRESHOLD ROW_NUMBER
SAMPLE SELECT START_TIME STEP STRING THEN TIME TIMESTAMP TIMEZONE
TRUE USING VALUE WEEKOFYEAR WHEN WHERE WITH WORKDAY_CALENDAR YES
The reserved words also include calendar keywords such as NOW, PREVIOUS_HOUR and interval units such as MINUTE, HOUR.
Literals
The literal is a constant value specified in the query, such as 'nurswvml007', 75, or '2017-08-15T00:00:00Z'. The database supports literals for string, timestamp, and number data types, as well as the NULL literal.
-- string literal
WHERE entity = 'nurswgvml007'
-- timestamp literal
WHERE datetime >= '2017-08-15T00:00:00Z'
-- number literal
WHERE value < 75
The string and timestamp literals must be enclosed in single quotation marks.
A literal value containing single quotes can be escaped by doubling the single quote symbol.
-- literal = a'b
WHERE entity LIKE '%a''b%'
NULL
The NULL literal represents null, or unknown value. Scalar expressions with arithmetic operators such as number + NULL produce NULL if any operand is NULL.
Likewise, numeric and string operators, except IS NULL and IS NOT NULL, return NULL if any operand is NULL.
The IS NULL expr operator returns true if the expression is NULL or NaN.
The IS NOT NULL expr operator returns true if the expression is neither NULL nor NaN.
Assuming the tags.status column is NULL, or has no value:
| Result | Expression |
|---|---|
NULL | tags.status > 'a' |
NULL | tags.status <= 'a' |
NULL | tags.status <> 'a' |
NULL | tags.status = NULL |
NULL | tags.status <> NULL |
NULL | tags.status = tags.status |
true | tags.status IS NULL |
false | tags.status IS NOT NULL |
NULL | tags.status IS NULL AND tags.status = NULL |
Since the WHERE clause selects only rows that evaluate to true, conditions such as tags.{name} = 'a' OR tags.{name} != 'a' ignore rows with undefined {name} tag because both expressions evaluate to NULL and (NULL OR NULL) still returns NULL.
NULL and NaN values are ignored by aggregate and analytical functions.
Logical expressions treat NaN as NULL. Refer to the truth tables above for more details on how NULL is evaluated by logical operators.
Not a Number (NaN)
The database returns special values if the computation result cannot be represented with a real number, for example in case of division by zero or √ of a negative number.
The returned values follow the IEEE 754-2008 standard.
NaNfor indeterminate results such as0/0(zero divided by zero).NaNfor illegal values.- Signed Infinity for
x/0where x != 0.
Because the BIGINT data type does not support Infinity constant, the returned Double Infinity constant, when cast to BIGINT, is replaced with 9,223,372,036,854,775,807 or -9,223,372,036,854,775,808 depending on sign.
SELECT value, SQRT(value-1), value/0, 1/0, -1/0, 1/0-1/0
FROM "mpstat.cpu_busy"
LIMIT 1
| value | SQRT(value-1) | value/0 | 1111111111/0 | 1/0 | -1/0 | 1/0-1/0 |
|-------|---------------|---------|-----------------------|-----|------|---------|
| 0.0 | NaN | NaN | 9223372036854775807.0 | ∞ | -∞ | NaN |
The result of comparing NaN with another number is indeterminate (NULL).
The NaN can be compared similar to NULL using IS operator:
AND value IS NOT NULL
Case Sensitivity
- SQL reserved words are case-insensitive.
- Entity column values, metric column values, and tag names are case-insensitive, except in
LIKEandREGEXoperators. - Text column values are case-sensitive.
- Tag column values are case-sensitive.
SELECT metric, entity, datetime, value, tags.*
FROM "df.disk_used"
WHERE datetime >= NOW - 5*MINUTE
AND entity = 'NurSwgvml007' -- case-INSENSITIVE entity value
AND tags.file_system = '/dev/mapper/vg_nurswgvml007-lv_root' -- case-sensitive tag value
| metric | entity | datetime | value | tags.mount_point | tags.file_system |
|--------------|--------------|----------------------|-----------|------------------|-------------------------------------|
| df.disk_used | nurswgvml007 | 2017-06-19T06:12:26Z | 8715136.0 | / | /dev/mapper/vg_nurswgvml007-lv_root |
Changing the case of a tag value condition tags.file_system = '/DEV/mapper/vg_nurswgvml007-lv_root' causes the database to return the TAG_VALUE not found error.
Arithmetic Operators
Arithmetic operators, including +, -, *, /, and % (modulo) can be applied to numeric columns or literal number.
The modulo operator
%returns the remainder of one number divided by another, for instance14 % 3(= 2).
Note
Arithmetic calculations are performed with double precision.
SELECT datetime, SUM(value), SUM(value + 100) / 2
FROM gc_invocations_per_minute
WHERE datetime >= NOW - 10*MINUTE
GROUP BY period(2 MINUTE)
SELECT AVG(metric1.value*2), SUM(metric1.value + metric2.value)
FROM metric1
JOIN metric2
WHERE metric1.datetime >= NOW - 10*MINUTE
Match Expressions
IN Expression
The IN expression returns true if the value on the left is equal to one of the comma-separated values enumerated in parentheses after the IN operator.
valueLeft [NOT] IN (valueRight [, valueRight])
The IN operator provides an alternative to multiple OR conditions.
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
WHERE entity IN ('nurswgvml006', 'nurswgvml007', 'nurswgvml008')
-- entity = 'nurswgvml006' OR entity = 'nurswgvml007' OR entity = 'nurswgvml008'
LIKE Expression
The LIKE expression returns true if the value matches the specified string pattern which supports % and _ wildcards.
Percent sign
%matches zero or more characters in the value.Underscore
_matches exactly one character in the value.
The comparison is case-sensitive, including entity and metric names which are converted to lower case when stored in the database.
SELECT datetime, entity, value, tags.mount_point, tags.file_system
FROM "df.disk_used_percent"
WHERE tags.file_system LIKE '/dev/%'
AND datetime >= PREVIOUS_HOUR
Wildcard symbols present in the pattern can be escaped with a backslash \ which serves as the default escape character.
-- Default escape character
WHERE tags.file_system LIKE '%a\_b%'
The escape character can be customized by adding an ESCAPE clause after the LIKE expression.
-- Custom escape character
WHERE tags.file_system LIKE '%a~_b%' ESCAPE '~'
In the example above, the underscore is evaluated as a regular character (not as a wildcard) because the underscore preceded by an ~ escape character.
Regular Expressions
The REGEX expression matches column value against a regular expression and returns true if the text is matched.
The comparison is case-sensitive, even for entity and metric names.
SELECT datetime, entity, value, tags.mount_point, tags.file_system
FROM "df.disk_used_percent"
WHERE tags.file_system REGEX '.*map.*|.*mnt.*'
AND datetime >= NOW - 1*HOUR
REGEX can be used to match one of multiple conditions as an alternative to multiple LIKE expressions.
WHERE entity = 'nurswgvml007'
AND (tags.file_system LIKE '%map%'
OR tags.file_system LIKE '%mnt%'
OR tags.file_system LIKE '%dev%')
WHERE entity = 'nurswgvml007'
AND tags.file_system REGEX '.*map.*|.*mnt.*|.*dev.*'
Special instructions such as (?i) for case-insensitive match can be added to customize the matching rules.
WHERE entity REGEX '(?i)Nurswgvml00.*'
BETWEEN Expression
The BETWEEN operator is inclusive by default and returns true if the test expression satisfies the lower range, the upper range, or is between the ranges.
The optional INCL and EXCL instructions override the default inclusion rules.
test_expr BETWEEN lower_range [ INCL | EXCL ] AND lower_range [ INCL | EXCL ]
-- returns TRUE
10 BETWEEN 1 AND 10
-- returns FALSE
10 BETWEEN 1 AND 10 EXCL
The EXCL instruction can be used to exclude the range boundaries, in particular the end of the date selection interval.
-- Ignores samples and periods recorded exactly at 12:00 and 13:00
SELECT datetime, value FROM timer_15m
WHERE datetime BETWEEN '2018-12-10 12:00:00' EXCL
AND '2018-12-10 13:00:00' EXCL
| datetime | value |
|---------------------------|-------|
| 2018-12-10T12:15:00.000Z | 0 |
| 2018-12-10T12:30:00.000Z | 0 |
| 2018-12-10T12:45:00.000Z | 0 |
-- Includes samples and periods recorded exactly at 12:00 and 13:00
SELECT datetime, value FROM timer_15m
WHERE datetime BETWEEN '2018-12-10 12:00:00'
AND '2018-12-10 13:00:00'
| datetime | value |
|---------------------------|-------|
| 2018-12-10T12:00:00.000Z | 0 |
| 2018-12-10T12:15:00.000Z | 0 |
| 2018-12-10T12:30:00.000Z | 0 |
| 2018-12-10T12:45:00.000Z | 0 |
| 2018-12-10T13:00:00.000Z | 0 |
CASE Expression
The CASE expression provides a way to use IF THEN logic in various parts of the query. Both simple and searched syntax options are supported.
Searched CASE Expression
The searched CASE expression evaluates a sequence of boolean expressions and returns a matching result expression.
CASE
WHEN search_expression THEN result_expression
[ WHEN search_expression THEN result_expression ]
[ ELSE result_expression ]
END
Each search_expression must return a boolean (true/false) value.
The result_expression can be a literal value (number, text) or an expression. Result expressions in the same CASE construct are allowed to return values of different data types.
If the data types are different (such as a number and a varchar), the database classifies the column with
JAVA_OBJECTto the JDBC driver.
If no search_expression is matched and the ELSE condition is not specified, the CASE expression returns NULL.
SELECT entity, tags.*, value,
CASE
WHEN LOCATE('//', tags.file_system) = 1 THEN 'nfs'
ELSE 'local'
END AS "FS_Type"
FROM "df.disk_used"
WHERE datetime >= CURRENT_HOUR
WITH ROW_NUMBER(entity, tags ORDER BY time DESC) <= 1
| entity | tags.file_system | tags.mount_point | value | FS_Type |
|--------------|-------------------------------------|------------------|------------|---------|
| nurswgvml006 | //u113411.store01/backup | /mnt/u113411 | 1791024684 | nfs |
| nurswgvml006 | /dev/mapper/vg_nurswgvml006-lv_root | / | 6045216 | local |
| nurswgvml006 | /dev/sdc1 | /media/datadrive | 56934368 | local |
| nurswgvml007 | //u113563.store02/backup | /mnt/u113563 | 1791024684 | nfs |
| nurswgvml007 | /dev/mapper/vg_nurswgvml007-lv_root | / | 9064008 | local |
SELECT entity, AVG(value),
CASE
WHEN AVG(value) < 20 THEN 'under-utilized'
WHEN AVG(value) > 80 THEN 'over-utilized'
ELSE 'right-sized'
END AS "Utilization"
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
GROUP BY entity
The CASE expression can be used to handle NULL and NaN values:
SELECT entity, datetime, value, text,
CASE
WHEN value IS NULL THEN -1
ELSE value
END,
CASE
WHEN text IS NULL THEN 'CASE: text is NULL'
ELSE text
END
FROM atsd_series
WHERE metric IN ('temperature', 'status')
AND datetime >= '2017-10-13T08:00:00Z'
Simple CASE Expression
The simple CASE expression compares the input_expression with compare_expressions and returns the result_expression when the comparison is true.
CASE input_expression
WHEN compare_expression THEN result_expression
[ WHEN compare_expression THEN result_expression ]
[ ELSE result_expression ]
END
SELECT entity, datetime, value,
CASE entity
WHEN 'nurswgvml006' THEN 'NUR-1'
WHEN 'nurswgvml301' OR 'nurswgvml302' THEN 'NUR-3'
ELSE 'Unknown'
END AS "location"
FROM "mpstat.cpu_busy"
WHERE datetime >= PREVIOUS_MINUTE
The CASE expressions can be nested by using CASE within the result_expression:
CASE date_format(time, 'yyyy')
WHEN '2016' THEN
CASE
WHEN IS_WEEKDAY(time, 'USA') THEN '16'
ELSE '17'
END
WHEN '2017' THEN '18'
WHEN '2018' THEN '17'
ELSE '15'
END AS "Tax Day"
Interval Condition
An interval condition determines the date range for the retrieved samples and is specified in the WHERE clause using the datetime or time column.
The datetime column accepts literal dates whereas the time column accepts Unix time in milliseconds. Both columns support calendar expressions.
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2017-12-10T00:00:00Z'
AND '2017-12-10T01:00:00Z'
-- time BETWEEN 1512864000000 AND 1512867600000
-- datetime >= NOW - 1*DAY
The above query selects samples recorded between 00:00 and 01:00 on December 10, 2017 in the UTC time zone. This includes samples recorded exactly at 00:00:00 and 01:00:00 because the BETWEEN operator is inclusive by default.
`BETWEEN` is inclusive
column BETWEEN a AND b is equivalent to column >= a AND column <= b.
To exclude the end of the selection interval, add the EXCL instruction to override the default BETWEEN behavior.
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
-- Exclude samples recorded at '2017-12-10T01:00:00Z'
WHERE datetime BETWEEN '2017-12-10T00:00:00Z'
AND '2017-12-10T01:00:00Z' EXCL
The datetime column accepts literal dates in one of the following formats:
| Format | Time Zone or UTC Offset | Examples |
|---|---|---|
yyyy-MM-ddTHH:mm:ss[.S](Z\|±hh[:]mm) | As specified | 2017-12-10T15:30:00.077Z2017-12-10T15:30:00Z2017-12-10T15:30:00-05:002017-12-10T15:30:00-0500 |
yyyy-MM-dd HH:mm:ss[.S] | Database or query | 2017-12-10 15:30:00.0772017-12-10 15:30:00 |
yyyy[-MM[-dd]] | Database or query | 20172017-122017-12-15 |
The UTC time zone is specified as the Z letter or as the zero UTC offset +00:00 (+0000).
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2017-12-10T14:00:15Z'
AND '2017-12-10T14:30:00.077Z'
-- WHERE datetime BETWEEN '2017-12-10 14:00:15' AND '2017-12-11 14:30:00.077'
-- WHERE datetime = '2017'
If the time zone is not specified, the literal date value is interpreted using the database time zone.
WHERE datetime BETWEEN '2017-12-10 14:00:15'
AND '2017-12-11 14:30:00.077'
The default time zone applied to literal dates in the query can be set explicitly using the WITH TIMEZONE clause.
WHERE datetime BETWEEN '2017-12-10 14:00:15'
AND '2017-12-11 14:30:00.077'
WITH TIMEZONE = 'US/Pacific'
Literal date values specified using short formats are expanded to the complete date by setting missing units to the first value in the allowed range.
'2017-05-23' == '2017-05-23 00:00:00''2017-05' == '2017-05-01 00:00:00''2017' == '2017-01-01 00:00:00'
The time column accepts Unix time in milliseconds:
SELECT time, entity, value
FROM "mpstat.cpu_busy"
WHERE time >= 1500300000000
-- 1500300000000 is equal to 2017-07-17 14:00:00 UTC
To round the dates to the nearest calendar period, use the date_round function.
WHERE datetime >= date_round(now, 5 MINUTE)
AND datetime < date_round(now + 5*minute, 5 MINUTE)
Optimizing Interval Queries
Using the date_format and EXTRACT functions in the WHERE condition and the GROUP BY clause can be inefficient as it causes the database to perform a full scan while comparing literal strings or numbers. Instead, filter dates using the indexed time or datetime column and apply the PERIOD function to aggregate records by interval.
WHEREClause
WHERE date_format(time, 'yyyy') > '2018' -- Slow: full scan with string comparison.
WHERE YEAR(time) > 2018 -- Slow: full scan with number comparison.
WHERE datetime >= '2018' -- Fast: date range scan using an indexed column.
WHERE datetime BETWEEN '2018' AND '2019' -- Fast: date range scan using an indexed column.
WHERE datetime >= '2018-01-01T00:00:00Z' -- Fast: date range scan using an indexed column.
GROUP BYClause
GROUP BY date_format(time, 'yyyy') -- Slow.
GROUP BY YEAR(time) -- Slow.
GROUP BY PERIOD(1 YEAR) -- Fast: built-in date aggregation
Calendar Expressions
The time and datetime columns support calendar keywords and expressions.
SELECT datetime, entity, value
FROM "mpstat.cpu_busy"
WHERE time >= NOW - 15 * MINUTE
AND datetime < CURRENT_MINUTE
The calendar expressions are evaluated according to the database time zone which can be customized using the ENDTIME function.
SELECT value, datetime,
date_format(time, 'yyyy-MM-ddTHH:mm:ssz', 'UTC') AS "UTC_datetime",
date_format(time, 'yyyy-MM-ddTHH:mm:ssz', 'US/Pacific') AS "PST_datetime"
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime BETWEEN ENDTIME(YESTERDAY, 'US/Pacific') AND ENDTIME(CURRENT_DAY, 'US/Pacific')
ORDER BY datetime
| value | datetime | UTC_datetime | PST_datetime |
|-------|----------------------|------------------------|------------------------|
| 6.86 | 2017-06-16T07:00:05Z | 2017-06-16T07:00:05UTC | 2017-06-16T00:00:05PDT |
| 6.06 | 2017-06-16T07:00:21Z | 2017-06-16T07:00:21UTC | 2017-06-16T00:00:21PDT |
....
| 3.03 | 2017-06-17T06:59:29Z | 2017-06-17T06:59:29UTC | 2017-06-16T23:59:29PDT |
| 2.97 | 2017-06-17T06:59:45Z | 2017-06-17T06:59:45UTC | 2017-06-16T23:59:45PDT |
Local Time Boundaries
To specify the interval range in local time, use the date_parse function to convert the timestamp literal into Unix time with millisecond precision.
SELECT datetime as utc_time, date_format(time, 'yyyy-MM-dd HH:mm:ss', 'Europe/Vienna') AS local_datetime, value
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND time >= date_parse('2017-06-15 12:00:00', 'yyyy-MM-dd HH:mm:ss', 'Europe/Vienna')
AND time < date_parse('2017-06-18 12:00:00', 'yyyy-MM-dd HH:mm:ss', 'Europe/Vienna')
| utc_time | local_datetime | value |
|---------------------|---------------------|--------|
| 2017-06-15 10:00:15 | 2017-06-15 12:00:15 | 4.9500 |
| 2017-06-15 10:00:31 | 2017-06-15 12:00:31 | 3.0000 |
| 2017-06-15 10:00:47 | 2017-06-15 12:00:47 | 3.0900 |
Converting a date to milliseconds and comparing it to the time column is more efficient than comparing formatted strings:
date_format(time, 'yyyy-MM-dd HH:mm:ss', 'Europe/Vienna') >= '2017-05-01 12:00:00'
Entity Time Zone
To select rows for a date range based on the local time zone of each entity, supply entity.timeZone column as an argument to the ENDTIME function.
SELECT entity, entity.timeZone,
AVG(value),
date_format(time, 'yyyy-MM-dd HH:mm z', 'UTC') AS "Period Start: UTC datetime",
date_format(time, 'yyyy-MM-dd HH:mm z', entity.timeZone) AS "Period Start: Local datetime"
FROM "mpstat.cpu_busy"
WHERE datetime >= ENDTIME(PREVIOUS_DAY, entity.timeZone)
AND datetime < ENDTIME(CURRENT_DAY, entity.timeZone)
GROUP BY entity, PERIOD(1 DAY, entity.timeZone)
| entity | entity.timeZone | avg(value) | Period Start: UTC datetime | Period Start: Local datetime |
|--------------|-----------------|------------|----------------------------|------------------------------|
| nurswgvml007 | PST | 12.3 | 2017-08-17 07:00 UTC | 2017-08-17 00:00 PDT |
| nurswgvml006 | US/Mountain | 9.2 | 2017-08-17 06:00 UTC | 2017-08-17 00:00 MDT |
| nurswgvml010 | null | 5.8 | 2017-08-17 00:00 UTC | 2017-08-17 00:00 GMT |
Multiple Intervals
Multiple time intervals can be selected using the OR operator.
SELECT datetime, value
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND (datetime BETWEEN '2017-04-02T14:00:00Z' AND '2017-04-02T14:01:00Z'
OR datetime BETWEEN '2017-04-04T16:00:00Z' AND '2017-04-04T16:01:00Z')
| datetime | value |
|----------------------|-------|
| 2017-04-02T14:00:04Z | 80.8 | start
| 2017-04-02T14:00:20Z | 64.7 |
| 2017-04-02T14:00:36Z | 5.0 |
| 2017-04-02T14:00:52Z | 100.0 | end
| 2017-04-04T16:00:06Z | 54.6 | start
| 2017-04-04T16:00:22Z | 6.0 |
| 2017-04-04T16:00:38Z | 81.0 |
| 2017-04-04T16:00:54Z | 38.8 | end
Multiple intervals are treated separately for the purpose of interpolating and regularizing values. In particular, the values between such intervals are not interpolated.
Interval Subqueries
As an alternative to specifying the lower and upper boundaries manually, the BETWEEN operator retrieves the time range with a subquery.
SELECT datetime, value
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime BETWEEN (
SELECT datetime FROM "maintenance-rfc"
WHERE entity = 'nurswgvml007'
ORDER BY datetime
)
| datetime | value |
|----------------------|-------|
| 2017-04-03T01:00:09Z | 24.0 |
| 2017-04-03T01:00:25Z | 55.0 |
...
| 2017-04-03T01:14:17Z | 4.0 |
| 2017-04-03T01:14:33Z | 4.1 |
| 2017-04-03T01:14:49Z | 63.0 |
Grouping
The GROUP BY clause groups records into rows that have matching values for the specified grouping columns.
SELECT entity, AVG(value) AS Cpu_Avg
FROM "mpstat.cpu_busy"
WHERE entity IN ('nurswgvml007', 'nurswgvml006', 'nurswgvml011')
AND datetime >= CURRENT_HOUR
GROUP BY entity
| entity | Cpu_Avg |
|--------------|---------|
| nurswgvml006 | 99.8 |
| nurswgvml007 | 15.2 |
| nurswgvml011 | 5.7 |
A special grouping column PERIOD calculates the start and end of the period to which the record belongs.
SELECT datetime, AVG(value) AS Cpu_Avg
FROM "mpstat.cpu_busy"
WHERE entity IN ('nurswgvml007', 'nurswgvml006', 'nurswgvml011')
AND datetime >= CURRENT_HOUR
GROUP BY period(5 MINUTE)
| datetime | Cpu_Avg |
|----------------------|---------|
| 2017-06-18T22:00:00Z | 43.2 |
| 2017-06-18T22:05:00Z | 35.3 |
| 2017-06-18T22:10:00Z | 5.0 |
Date Aggregation
Date aggregation is a special type of GROUP BY operation that involves grouping the values into intervals of equal duration, or periods.
Period
Period is a repeating time interval used to group values occurred within each interval into sets to apply aggregate functions to each set separately.
Period syntax:
GROUP BY PERIOD(int count varchar unit [, option])
option = interpolate | align | extend | timezone
interpolate= PREVIOUS | NEXT | LINEAR | VALUE {number}extend= EXTENDalign= START_TIME, END_TIME, FIRST_VALUE_TIME, CALENDARtimezone= Time Zone ID as literal string, orentity.timeZone/metric.timeZonecolumn.
The PERIOD options can be specified in any order and are separated by a comma.
PERIOD(5 MINUTE)
PERIOD(5 MINUTE, END_TIME)
PERIOD(5 MINUTE, CALENDAR, VALUE 0)
PERIOD(1 HOUR, LINEAR, EXTEND)
PERIOD(1 DAY, 'US/Eastern')
PERIOD(1 DAY, entity.timeZone)
| Name | Description |
|---|---|
count | [Required] Number of time units contained in the period. |
unit | [Required] Time unit such as HOUR, DAY, WEEK, MONTH, QUARTER, YEAR. |
interpolate | Apply an interpolation function, such as LINEAR or VALUE 0, to add missing periods. |
extend | Add missing periods at the beginning and end of the selection interval using VALUE {n} or the PREVIOUS and NEXT interpolation functions. |
align | Align the period start and end. Default: CALENDAR.Allowed values: CALENDAR, START_TIME, END_TIME, FIRST_VALUE_TIME.Refer to period alignment. |
timezone | Time zone for aligning periods in CALENDAR mode, such as 'US/Eastern', 'UTC', or entity.timeZone.Default: current database time zone. |
SELECT entity, date_format(PERIOD(5 MINUTE, END_TIME)), AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR AND datetime < NEXT_HOUR
GROUP BY entity, PERIOD(5 MINUTE, END_TIME)
The period specified in the GROUP BY clause can be entered without option fields in the SELECT expression.
SELECT entity, PERIOD(5 MINUTE), AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR AND datetime < NEXT_HOUR
GROUP BY entity, PERIOD(5 MINUTE, END_TIME)
In grouping queries, the time column returns the same value as PERIOD(), and datetime returns the same value as date_format(PERIOD()).
SELECT entity, datetime, AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR AND datetime < NEXT_HOUR
GROUP BY entity, PERIOD(5 MINUTE, END_TIME)
Period Alignment
The default CALENDAR setting creates calendar-aligned periods using the duration specified in the PERIOD function.
For example, period(1 HOUR) initializes 1-hour long periods starting at 0 minutes of each hour within the selection interval.
| Alignment | Description |
|---|---|
CALENDAR | Period starts are aligned to the calendar. |
START_TIME | First period begins at start time specified in the query. |
FIRST_VALUE_TIME | First period begins at the time of first retrieved value. |
END_TIME | Last period ends on end time specified in the query. |
- For the
START_TIMEandEND_TIMEoptions, theWHEREclause must contain the start and end time of the selection interval, respectively.
SELECT entity, datetime, COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= now-1*HOUR AND datetime < now
AND entity = 'nurswgvml006'
GROUP BY entity, PERIOD(5 MINUTE, END_TIME)
CALENDAR Alignment
The CALENDAR alignment calculates the initial period according to the rules below and creates subsequent periods by incrementing the duration specified by the PERIOD function. The initial period is defined as the earliest period that intersects with the selection interval.
- The start time of a selection interval is rounded to calculate the base time using the rule table below.
- If the period starting with the base time intersects with the selection interval, it becomes the initial period.
- Otherwise, the period starting with base time is incremented (decremented if base time exceeds start time) to find the earliest period intersecting with the selection interval. This period becomes the initial period.
Rounding Rules
| Time Unit | Base Time (Rounded) |
|---|---|
| MILLISECOND | 0m:0s in a given hour. |
| SECOND | 0m:0s in a given hour. |
| MINUTE | 0m:0s in a given hour. |
| HOUR | 0h:0m:0s on a given day. |
| DAY | 0h:0m:0s on the 1st day in a given month. |
| WEEK | 0h:0m:0s on the 1st Monday in a given month. |
| MONTH | 0h:0m:0s on January 1st in a given year. |
| QUARTER | 0h:0m:0s on January 1st in a given year. |
| YEAR | 0h:0m:0s on January 1st, 1970. |
Examples:
| Period | Start Time | End Time | _base time_ | Initial Period | 2nd Period | Last Period |
|------------|-------------------|-------------------|-------------------|-------------------|-------------------|------------------|
| 45 MINUTE | 2017-06-20 15:05 | 2017-06-24 00:00 | 2017-06-20 15:00 | 2017-06-20 15:00 | 2017-06-20 15:45 | 2017-06-23 23:15 |
| 45 MINUTE | 2017-06-20 15:00 | 2017-06-24 00:00 | 2017-06-20 15:00 | 2017-06-20 15:00 | 2017-06-20 15:45 | 2017-06-23 23:15 |
| 45 MINUTE | 2017-06-20 15:55 | 2017-06-24 00:00 | 2017-06-20 15:00 | 2017-06-20 15:45 | 2017-06-20 16:30 | 2017-06-23 23:15 |
| 60 MINUTE | 2017-06-20 15:30 | 2017-06-24 00:00 | 2017-06-20 15:00 | 2017-06-20 15:00 | 2017-06-20 16:00 | 2017-06-23 23:00 |
| 1 HOUR | 2017-06-20 15:30 | 2017-06-24 00:00 | 2017-06-20 00:00 | 2017-06-20 15:00 | 2017-06-20 16:00 | 2017-06-23 23:00 |
| 1 HOUR | 2017-06-20 16:00 | 2017-06-24 00:00 | 2017-06-20 00:00 | 2017-06-20 16:00 | 2017-06-20 17:00 | 2017-06-23 23:00 |
| 1 HOUR | 2017-06-20 16:05 | 2017-06-23 23:55 | 2017-06-20 00:00 | 2017-06-20 16:00 | 2017-06-20 17:00 | 2017-06-23 23:00 |
| 7 HOUR | 2017-06-20 16:00 | 2017-06-24 00:00 | 2017-06-20 00:00 | 2017-06-20 14:00 | 2017-06-20 21:00 | 2017-06-23 19:00 |
| 10 HOUR | 2017-06-20 16:00 | 2017-06-24 00:00 | 2017-06-20 00:00 | 2017-06-20 10:00 | 2017-06-20 20:00 | 2017-06-23 18:00 |
| 1 DAY | 2017-06-01 16:00 | 2017-06-24 00:00 | 2017-06-01 00:00 | 2017-06-01 00:00 | 2017-06-02 00:00 | 2017-06-23 00:00 |
| 2 DAY | 2017-06-01 16:00 | 2017-06-24 00:00 | 2017-06-01 00:00 | 2017-06-01 00:00 | 2017-06-03 00:00 | 2017-06-23 00:00 |
| 5 DAY | 2017-06-01 16:00 | 2017-06-24 00:00 | 2017-06-01 00:00 | 2017-06-01 00:00 | 2017-06-11 00:00 | 2017-06-21 00:00 |
| 1 WEEK | 2017-06-01 16:00 | 2017-06-24 00:00 | 2017-06-06 00:00 | 2017-05-30 00:00 | 2017-06-06 00:00 | 2017-06-20 00:00 |
| 1 WEEK | 2017-06-07 16:00 | 2017-06-24 00:00 | 2017-06-06 00:00 | 2017-06-06 00:00 | 2017-06-13 00:00 | 2017-06-20 00:00 |
| 1 WEEK | 2017-05-01 16:00 | 2017-05-24 00:00 | 2017-05-02 00:00 | 2017-04-25 00:00 | 2017-05-02 00:00 | 2017-05-23 00:00 |
| 1 WEEK | 2017-06-01 00:00 | 2017-06-02 00:00 | 2017-06-06 00:00 | 2017-05-30 00:00 | - | - |
For DAY, WEEK, MONTH, QUARTER, and YEAR units, the start of the day is determined according to the database time zone, unless a user-defined time zone is specified as an option, for example GROUP BY entity, PERIOD(1 MONTH, 'UTC').
END_TIME Alignment
- If the end time in the query is inclusive, 1 millisecond is added to the period end time since the period end time must be exclusive.
SELECT entity, datetime, COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= '2017-06-18T10:02:00Z' AND datetime < '2017-06-18T10:32:00Z'
AND entity = 'nurswgvml007'
GROUP BY entity, PERIOD(10 MINUTE, END_TIME)
| entity | datetime | COUNT(value) |
|--------------|--------------------------|--------------|
| nurswgvml007 | 2017-06-18T10:02:00.000Z | 38.0 |
| nurswgvml007 | 2017-06-18T10:12:00.000Z | 37.0 |
| nurswgvml007 | 2017-06-18T10:22:00.000Z | 38.0 |
SELECT entity, datetime, COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= '2017-06-18T10:02:00Z' AND datetime <= '2017-06-18T10:32:00Z'
AND entity = 'nurswgvml007'
GROUP BY entity, PERIOD(10 MINUTE, END_TIME)
| entity | datetime | COUNT(value) |
|--------------|--------------------------|--------------|
| nurswgvml007 | 2017-06-18T10:02:00.001Z | 38.0 |
| nurswgvml007 | 2017-06-18T10:12:00.001Z | 37.0 |
| nurswgvml007 | 2017-06-18T10:22:00.001Z | 38.0 |
START_TIME Alignment
1 millisecond is added to the period start if the start time in the query is exclusive.
SELECT entity, datetime, COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime > '2017-06-18T10:02:00Z' AND datetime < '2017-06-18T10:32:00Z'
AND entity = 'nurswgvml007'
GROUP BY entity, PERIOD(10 MINUTE, START_TIME)
| entity | datetime | COUNT(value) |
|--------------|--------------------------|--------------|
| nurswgvml007 | 2017-06-18T10:02:00.001Z | 38.0 |
| nurswgvml007 | 2017-06-18T10:12:00.001Z | 37.0 |
| nurswgvml007 | 2017-06-18T10:22:00.001Z | 38.0 |
Interpolation
By default, if a period specified in the GROUP BY clause does not contain any detailed values, such period is excluded from the results.
The behavior can be changed by referencing an interpolation function as part of the PERIOD function.
| Name | Description |
|---|---|
PREVIOUS | Set value for the period based on the previous period value. |
NEXT | Set value for the period based on the next period value. |
LINEAR | Calculate period value using linear interpolation between previous and next period values. |
VALUE {d} | Set value for the period to constant number d. |
SELECT entity, period(5 MINUTE), AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
GROUP BY entity, period(5 MINUTE, LINEAR)
EXTEND Option
Include an optional EXTEND parameter to the PERIOD function to append missing periods at the beginning and the end of the selection interval.
Leading and trailing period values are set with the VALUE {n} function if such a function is specified.
period(5 MINUTE, VALUE 0, EXTEND)
Otherwise, in absence of the VALUE {n} function, the EXTEND option sets period values at the beginning of the interval with the NEXT function, whereas values at the end are set with the PREVIOUS function.
SELECT entity, period(5 MINUTE), AVG(value)
FROM "mpstat.cpu_busy" WHERE datetime >= CURRENT_HOUR
GROUP BY entity, period(5 MINUTE, LINEAR, EXTEND)
Interpolation Examples
Regularization
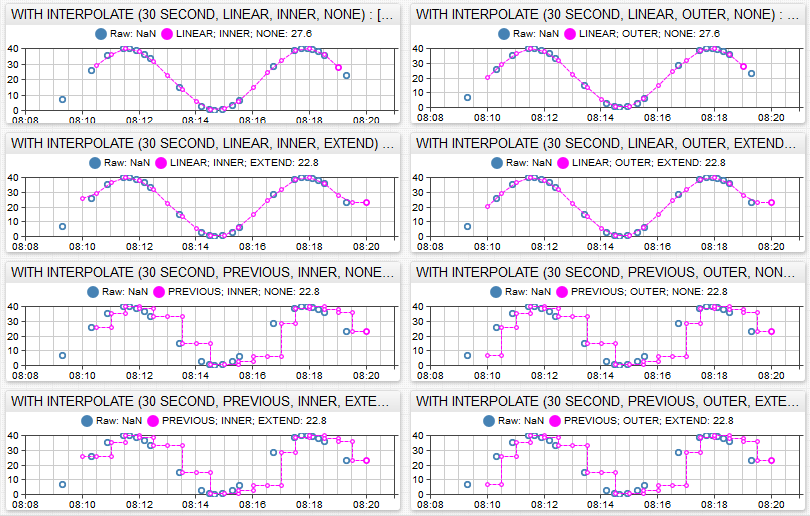
The WITH INTERPOLATE clause provides a way to transform unevenly spaced time series into a regular series.
The underlying transformation applies a linear interpolation or step function to calculate values at regular intervals.
SELECT datetime, value
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime >= '2017-09-17T08:00:00Z' AND datetime < '2017-09-17T08:02:00Z'
WITH INTERPOLATE(30 SECOND)
| raw time | regular time |
|----------------------|----------------------|
| 2017-09-17T08:00:00Z | 2017-09-17T08:00:00Z |
| ...........08:00:26Z | ...........08:00:30Z |
| ...........08:01:14Z | ...........08:01:00Z |
| ...........08:01:30Z | ...........08:01:30Z |
Syntax
WITH INTERPOLATE (period [, inter_func[, boundary[, fill [, alignment[, timezone]]]]])
The WITH INTERPOLATE clause is included prior to the ORDER BY and LIMIT clauses.
If the query retrieves multiple series, the interpolation is applied to each series separately.
If the WHERE condition includes multiple date ranges, the interpolation is performed for each date range and series separately.
Example:
WITH INTERPOLATE (1 MINUTE, LINEAR, OUTER, VALUE NaN, START_TIME)
Parameters:
| Name | Description |
|---|---|
period | Regular interval for aligning interpolated values. |
inter_func | Interpolation function to calculate values at regular timestamps based on adjacent values. Default: LINEAR. |
boundary | Retrieval of raw values outside of the selection interval to interpolate leading and trailing values. Default: INNER. |
fill | Method for filling missing values at the beginning and the end of the selection interval. Default: false. |
alignment | Aligns regular timestamps based on calendar or start time. Default: CALENDAR. |
timezone | Time zone applied in CALENDAR alignment to periods equal or greater than 1 day. |

Interpolation Period
The interpolation period is specified as a count unit, for example 5 MINUTE, or DETAIL.
| Name | Description |
|---|---|
| count | [Required] Number of time units contained in the period. |
| unit | [Required] Time unit such as HOUR, DAY, WEEK, MONTH, QUARTER, YEAR. |
The DETAIL mode can be used to fill missing values in FULL OUTER JOIN queries while retaining the original timestamps of the merged series.
Interpolation Function
| Name | Description |
|---|---|
LINEAR | Calculates the value at the given timestamp by linearly interpolating prior and next values. |
PREVIOUS | Sets the value at the given timestamp based on the previously recorded raw value. This step-like function is appropriate for metrics with discrete values (digital signals). |
AUTO | [Default] Applies an interpolation function (LINEAR or PREVIOUS) based on the metric Interpolation setting.If multiple metrics are specified in the query, AUTO applies its own interpolation mode for each metric. |
NaN(Not-A-Number) values are ignored from interpolation.- The
valuecondition in theWHEREclause applies to interpolated series values instead of raw values. Filtering out raw values prior to interpolation is not supported.
Boundary
| Name | Description |
|---|---|
INNER | [Default] Performs calculations based on raw values located within the specified selection interval. |
OUTER | Retrieves prior and next raw values outside of the selection interval to interpolate leading and trailing values. |
Fill
| Name | Description |
|---|---|
false | [Default] No missing values are filled. The rows for periods without interpolated values are not included in the result. |
true | Missing values at the beginning of the interval are set to first raw value within the interval. Missing values at the end of the interval are set to last raw value within the interval. This option requires that both start and end time are specified in the query. |
VALUE {n} | Sets missing values to {n} which can be a decimal number or a NaN (Not a Number)For example: VALUE 0 or VALUE NaN. |
Alignment
| Name | Description |
|---|---|
CALENDAR | [Default] Aligns regular timestamps according to the specified time zone. If time zone is not specified, the interval is split into periods based on the database time zone. |
START_TIME | Starts regular timestamps at the start time of the selection interval. This option requires that both start and end time are specified in the query. |
Interpolation Time Zone
| Name | Description |
|---|---|
null | [Default] The database time zone is used to split the selection interval into periods greater than 1 day. |
timezone id | The literal string with the time zone identifier. |
entity.timeZone ormetric.timeZone | The time zone of the entity or metric. |
Regularization Examples
HAVING filter
The HAVING clause filters grouped rows. It eliminates grouped rows that do not match the specified condition which can contain one or multiple aggregate functions.
HAVING aggregate_function operator value
SELECT entity, AVG(value) AS Cpu_Avg
FROM "mpstat.cpu_busy"
WHERE entity IN ('nurswgvml007', 'nurswgvml006', 'nurswgvml011')
AND datetime >= CURRENT_HOUR
GROUP BY entity
HAVING AVG(value) > 10
| entity | Cpu_Avg |
|--------------|---------|
| nurswgvml006 | 99.8 |
| nurswgvml007 | 14.3 |
HAVING AVG(value) > 10 OR MAX(value) > 90
Partitioning
Partitioning is implemented with the ROW_NUMBER function, which returns the sequential number of a row within a partition, starting with 1 for the first row in each partition.
A partition is a subset of all rows within the result set, grouped by an entity or series tags. Each row in the result set can belong to only one partition. The partition includes only rows that satisfy the WITH ROW_NUMBER condition.
Sample result set, partitioned by entity and ordered by time:
|--------------|----------------------|-------| ROW_NUMBER
| nurswgvml006 | 2017-06-18T12:00:05Z | 66.0 | 1
| nurswgvml006 | 2017-06-18T12:00:21Z | 8.1 | 2
| nurswgvml007 | 2017-06-18T12:00:03Z | 18.2 | 1
| nurswgvml007 | 2017-06-18T12:00:19Z | 67.7 | 2
| nurswgvml010 | 2017-06-18T12:00:14Z | 0.5 | 1
| nurswgvml011 | 2017-06-18T12:00:10Z | 100.0 | 1
| nurswgvml011 | 2017-06-18T12:00:26Z | 4.0 | 2
| nurswgvml011 | 2017-06-18T12:00:29Z | 0.0 | 3
::: Difference between Partitioning and Grouping
Unlike the GROUP BY clause, partitioning does not reduce the row count. Roll-up functions applied in the GROUP BY clause are called aggregate functions, whereas the functions applied to partitions are called windowing or analytical functions.
:::
ROW_NUMBER
ROW_NUMBER({partitioning columns} ORDER BY {ordering columns [direction]})
The {partitioning columns} clause must contain one or multiple columns for splitting the rows, for example entity, tags, or entity, tags.
Since the combination of the
metric,entityandtagscolumns constitutes the primary key of the series, theROW_NUMBER(metric, entity, tags ...)expression effectively creates a partition for each series.
The {ordering columns [direction]} can refer to any column of the FROM clause with an optional ASC/DESC sorting direction.
| Example | Description |
|---|---|
ROW_NUMBER(entity ORDER BY time) | Partition rows by entity column.Sort rows within each partition by time in ascending order. |
ROW_NUMBER(metric, entity, tags ORDER BY time DESC) | Partition rows by entity and tags columns in such a way that each partition contains rows for only one series.Sort rows within each partition by time in descending order. |
ROW_NUMBER(value ORDER BY value DESC) | Partition rows by value column.Sort rows by decreasing value column values. |
ROW_NUMBER(entity ORDER BY AVG(value)) | Partition rows by entity column.Sort rows within each partition by average value in each period. Aggregate functions in {ordering columns} are allowed when partitioning is applied to grouped rows. |
Analytical Functions
| Name | Description | Example |
|---|---|---|
COUNT | Count of samples. | COUNT(value) |
SUM | Sum of values. | SUM(value) |
MIN | Minimum of values. | MIN(value) |
MAX | Maximum of values. | MAX(value) |
AVG | Average of values. | AVG(value) |
PRODUCT | Product of values. | PRODUCT(values) |
WAVG | Weighted average of values. | WAVG(value) |
WTAVG | Time-weighted average of values. | WTAVG(value) |
EMA | Exponential moving average of values. The function requires smoothing factor as the first argument. | EMA(0.1, value) |
REGR_INTERCEPT | Slope of the linear regression line. | REGR_INTERCEPT(value, time) |
REGR_SLOPE | Intercept of the linear regression line. | REGR_SLOPE(value, time)*(time+3*60000) |
For an unbound window ROW_NUMBER(...) > 0, an analytical function is applied to all rows in the partition. For a sliding window, the function is applied to a subset of rows matching the row number condition.
Partition Condition
The partition includes rows that satisfy the WITH ROW_NUMBER condition which compares the row number with a constant value or the current row number.
- Top-N rows. Includes rows
1to5with largest values.
WITH ROW_NUMBER(entity ORDER BY value DESC) <= 5
- Unbound window. Includes all rows. Applies analytical functions to all rows from first to current.
WITH ROW_NUMBER(entity ORDER BY time) > 0
- Sliding count-based window. Includes all rows. Applies analytical functions to the
10preceding rows.
WITH ROW_NUMBER(entity ORDER BY time) BETWEEN 10 PRECEDING AND CURRENT ROW
- Sliding time-based window. Includes all rows. Applies analytical functions to the preceding rows in the 5-minute interval.
WITH ROW_NUMBER(entity ORDER BY time) BETWEEN 5 MINUTE PRECEDING AND CURRENT ROW
Partition Ordering
Each row in the partition is assigned an ordinal row number, starting with 1, which can be used to filter sorted rows within each partition.
WITH ROW_NUMBER(entity ORDER BY value) <= 10
The row numbers can be accessed in the SELECT expression using the row_number(), rank() and dense_rank() functions which return an ordinal integer number for each row, starting with 1. The numbers are assigned separately within each partition, after the rows in each partition are sorted according to the {ordering columns [direction]} clause.
| Function | Description |
|---|---|
row_number() | Continuously incrementing, unique row number assigned to each row in the partition. Row numbers are unique within each partition. |
rank() | Incrementing rank number assigned to each row in the partition. Rows with the same values in the sorted columns are assigned the same rank. The rank is incremented by the number of rows with the same values, in which case the sequence of rank() numbers has gaps and is not consecutive. |
dense_rank() | Same as rank() function except dense_rank() numbers are continuously incremented and thus are consecutive. |
WITH ROW_NUMBER(entity, tags ORDER BY value DESC) > 0
| value | row_number() | rank() | dense_rank() |
|--------|---------------|---------|--------------|
| 80 | 1 | 1 | 1 |
| 80 | 2 | 1 | 1 |
| 79 | 3 | 3 | 2 |
| 79 | 4 | 3 | 2 |
| 78 | 5 | 5 | 3 |
| 77 | 6 | 6 | 4 |
| 76 | 7 | 7 | 5 |
Partitioning Examples
- Return the largest values (
ORDER BY value DESC) for each partition.
SELECT entity, datetime, value
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2018-06-18T12:00:00Z' AND '2018-06-18T13:00:00Z' EXCL
WITH ROW_NUMBER(entity ORDER BY time DESC) <= 1
ORDER BY entity, datetime
| entity | datetime | value |
|--------------|---------------------|-------|
| nurswgvml006 | 2018-06-18 12:45:58 | 29.5 |
| nurswgvml007 | 2018-06-18 12:58:55 | 100.0 |
| nurswgvml010 | 2018-06-18 12:55:04 | 100.0 |
| nurswgvml301 | 2018-06-18 12:22:02 | 11.2 |
| nurswgvml501 | 2018-06-18 12:09:01 | 29.2 |
| nurswgvml502 | 2018-06-18 12:59:32 | 100.0 |
- Return most recent records (
ORDER BY time DESC) for each partition.
SELECT entity, datetime, value
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2018-06-18T12:00:00Z' AND '2018-06-18T13:00:00Z' EXCL
WITH ROW_NUMBER(entity ORDER BY time DESC) <= 1
ORDER BY entity, datetime
| entity | datetime | value |
|--------------|---------------------|-------|
| nurswgvml006 | 2018-06-18 12:59:50 | 1.2 |
| nurswgvml007 | 2018-06-18 12:59:59 | 65.0 |
| nurswgvml010 | 2018-06-18 12:59:52 | 3.0 |
| nurswgvml301 | 2018-06-18 12:59:46 | 1.0 |
| nurswgvml501 | 2018-06-18 12:59:58 | 6.2 |
| nurswgvml502 | 2018-06-18 12:59:48 | 2.6 |
- Apply an analytical function to last
Nrecords.
SELECT entity,
AVG(value) --average is calculated from last 10 rows in each partition
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_HOUR
WITH ROW_NUMBER(entity ORDER BY time DESC) <= 10
GROUP BY entity
| entity | AVG(value) |
|--------------|------------|
| nurswgvml006 | 14.0 |
| nurswgvml007 | 5.5 |
| nurswgvml010 | 3.5 |
| nurswgvml301 | 0.4 |
| nurswgvml502 | 3.9 |
- Calculate sliding window statistics using analytical functions.
SELECT datetime, value, AVG(value), COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2018-06-18T12:00:00Z' AND '2018-06-18T13:00:00Z' EXCL
AND entity = 'nurswgvml007'
WITH ROW_NUMBER(entity ORDER BY time) BETWEEN 5 PRECEDING AND CURRENT ROW
ORDER BY entity, datetime
| datetime | value | avg(value) | count(value) |
|---------------------|-------|------------|--------------|
| 2018-06-18 12:00:13 | 12.2 | 12.2 | 1 |
| 2018-06-18 12:00:29 | 7.1 | 9.7 | 2 |
| 2018-06-18 12:00:45 | 8.0 | 9.1 | 3 |
| 2018-06-18 12:01:01 | 7.9 | 8.8 | 4 |
| 2018-06-18 12:01:17 | 27.3 | 12.5 | 5 |
| 2018-06-18 12:01:33 | 8.1 | 11.7 | 5 |
| 2018-06-18 12:01:49 | 8.1 | 11.9 | 5 |
| 2018-06-18 12:02:05 | 6.1 | 11.5 | 5 |
| 2018-06-18 12:02:21 | 9.2 | 11.7 | 5 |
| 2018-06-18 12:02:37 | 16.0 | 9.5 | 5 |
- Calculate statistics for an unbound window using analytical functions.
SELECT value, AVG(value) AS "SimpleAvg", WAVG(value) AS "WeightedAvg", EMA(0.10, value) AS "ExpAvg-0.10"
FROM timer_1m
WHERE datetime BETWEEN '2019-02-09T00:30:00Z' AND '2019-02-09T02:30:00Z'
WITH INTERPOLATE(5 minute, linear)
WITH ROW_NUMBER(entity, tags ORDER BY time) > 0
View ChartLab example.
| value | SimpleAvg | WeightedAvg | ExpAvg-0.10 |
|-------|-----------|-------------|-------------|
| 30.00 | 30.00 | 30.00 | 30.00 |
| 35.00 | 32.50 | 33.33 | 30.50 |
| 40.00 | 35.00 | 36.67 | 31.45 |
| 45.00 | 37.50 | 40.00 | 32.80 |
| 50.00 | 40.00 | 43.33 | 34.52 |
| 55.00 | 42.50 | 46.67 | 36.57 |
| 0.00 | 36.43 | 35.00 | 32.91 |
| 5.00 | 32.50 | 28.33 | 30.12 |
| 10.00 | 30.00 | 24.67 | 28.11 |
| 15.00 | 28.50 | 22.91 | 26.80 |
| 20.00 | 27.73 | 22.42 | 26.12 |
| 25.00 | 27.50 | 22.82 | 26.01 |
| 30.00 | 27.69 | 23.85 | 26.41 |
The ROW_NUMBER function can be included after the WHERE clause, as well as after the GROUP BY clause, in which case the function is applied to grouped rows.
SELECT entity, tags, MAX(value) - MIN(value) AS "Diff"
FROM "df.disk_used"
WHERE datetime >= CURRENT_DAY
-- fetch last 100 records for each series
WITH ROW_NUMBER(entity, tags ORDER BY time DESC) <= 100
GROUP BY entity, tags
HAVING MAX(value) - MIN(value) > 0
-- fetch top 3 series for each entity
WITH ROW_NUMBER(entity ORDER BY MAX(value) - MIN(value) DESC) <= 3
ORDER BY Diff DESC
If the GROUP BY clause contains a PERIOD column, the ROW_NUMBER function applied to grouped rows can refer to the same period as the grouping clause.
SELECT entity, tags.*, datetime, avg(value), count(value), first(value), last(value)
FROM "df.disk_used"
WHERE datetime >= '2017-01-09T00:00:00Z' AND datetime < '2017-01-09T02:00:00Z'
-- group by series (entity+tags) and 15-minute period
GROUP BY entity, tags, period(15 minute)
-- retain only 2 periods for each series (entity+tags)
WITH ROW_NUMBER(entity, tags ORDER BY period(15 minute)) <= 2
| entity | tags.file_system | datetime | avg(value) | count(value) | first(value) | last |
|--------------|-------------------------------------|----------------------|------------|--------------|--------------|-----------|
| nurswgvml006 | /dev/mapper/vg_nurswgvml006-lv_root | 2017-01-09T00:00:00Z | 6285986 | 60 | 6285696 | 6286312 |
| nurswgvml006 | /dev/mapper/vg_nurswgvml006-lv_root | 2017-01-09T00:15:00Z | 6286339 | 60 | 6286312 | 6286372 |
| nurswgvml006 | /dev/sdc1 | 2017-01-09T00:00:00Z | 57558921 | 60 | 57521944 | 57579272 |
| nurswgvml006 | /dev/sdc1 | 2017-01-09T00:15:00Z | 57600482 | 60 | 57580072 | 57510460 |
| nurswgvml007 | /dev/mapper/vg_nurswgvml007-lv_root | 2017-01-09T00:00:00Z | 9046720 | 60 | 9024392 | 9071064 |
| nurswgvml007 | /dev/mapper/vg_nurswgvml007-lv_root | 2017-01-09T00:15:00Z | 9005158 | 60 | 9071668 | 9010264 |
The row_number() column can be included in the SELECT expression and in the ORDER BY clause without specifying arguments required by the WITH ROW_NUMBER clause itself.
SELECT datetime, entity, value, row_number()
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2017-05-30T09:00:00Z' AND '2017-05-30T09:05:00Z'
WITH ROW_NUMBER(entity ORDER BY datetime DESC) <= 2
ORDER BY row_number() DESC
| datetime | entity | value | row_number() |
|----------------------|--------------|-------|--------------|
| 2017-05-30T09:04:42Z | nurswgvml007 | 1.0 | 2 |
| 2017-05-30T09:04:40Z | nurswgvml006 | 1.0 | 2 |
| 2017-05-30T09:04:38Z | nurswgvml010 | 0.2 | 2 |
| 2017-05-30T09:04:58Z | nurswgvml007 | 14.1 | 1 |
| 2017-05-30T09:04:56Z | nurswgvml006 | 1.0 | 1 |
| 2017-05-30T09:04:54Z | nurswgvml010 | 0.0 | 1 |
LAST_TIME Syntax
The last_time function returns the last time, in milliseconds, when data is received for a given series. It enables filtering of records based on the last insertion date for the given series.
WITH time comparison_operator last_time_expression
WITH last_time_expression comparison_operator time
timeis the pre-defined time column which represents the timestamp of the sample.- A
comparison_operatoris one of the following operators:>,>=,<,<=,=. - A
last_time_expressionconsists of thelast_timekeyword and an optional calendar expression.
WITH time >= last_time - 1*MINUTE
Calculate the average for the most recent hour for each series that received data in the current month:
SELECT entity, AVG(value), date_format(MAX(time)) AS Last_Date
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_MONTH
GROUP BY entity
WITH time >= last_time - 1*HOUR
WITH Clauses
The withExpr starts with WITH keyword and can contain the following expressions:
withExpr = ROW_NUMBER expr | LAST_TIME expr | INTERPOLATE expr | TIMEZONE expr
WITH ROW_NUMBER(entity ORDER BY time) < 2
WITH TIMEZONE = 'Europe/Vienna'
Multiple WITH clauses in the same query can be combined using comma.
withExpr [, withExpr]
WITH ROW_NUMBER(entity ORDER BY time) < 2, TIMEZONE = 'Europe/Vienna'
Ordering
The default sort order is undefined. Row ordering can be performed by adding the ORDER BY clause consisting of column name, column number (starting with 1), or an expression followed by direction (ASC or DESC).
SELECT entity, AVG(value) FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_DAY
GROUP BY entity
ORDER BY AVG(value) DESC, entity
| entity | AVG(value) |
|--------------|-----------:|
| nurswgvml006 | 19.2 |
| nurswgvml007 | 13.2 |
| nurswgvml011 | 5.1 |
| nurswgvml010 | 4.3 |
| nurswgvml502 | 4.3 |
| nurswgvml102 | 1.2 |
Column numbers can be used instead of column names. The number must be a positive integer representing the position of the column in the SELECT expression.
SELECT entity, AVG(value) FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_DAY
GROUP BY entity
ORDER BY 2 DESC, 1
In combination with LIMIT, ordering can be used to execute the top-N queries.
SELECT entity, AVG(value) FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_DAY
GROUP BY entity
ORDER BY AVG(value) DESC
LIMIT 2
| entity | AVG(value) |
|--------------|-----------:|
| nurswgvml006 | 19.3 |
| nurswgvml007 | 13.2 |
Collation
Strings are ordered lexicographically, based on Unicode values. NULL has the lowest possible value and is listed first when sorted in ascending order.
| ATSD | MySQL | PostgreSQL | Oracle |
|---|---|---|---|
| 0 U+0030 | 0 | 0 | 0 |
| 1 U+0031 | 1 | 1 | 1 |
| A U+0041 | A | a | A |
| B U+0042 | a | A | B |
| C U+0043 | B | b | C |
| T U+0054 | b | B | T |
| U U+0055 | C | C | U |
| a U+0061 | t | t | a |
| b U+0062 | T | T | b |
| t U+0074 | U | U | t |
| z U+007A | z | z | z |
Limiting
To reduce the number of rows returned by the database for a given query, add the LIMIT clause at the end of the query.
The LIMIT clause provides two syntax alternatives:
| Syntax | Example | Description |
|---|---|---|
LIMIT [offset,] count | LIMIT 3, 5 | Select 5 rows starting with 4th row |
LIMIT [offset,] count | LIMIT 0, 5 | Select 5 rows starting with 1st row |
LIMIT count OFFSET offset | LIMIT 5 OFFSET 3 | Select 5 rows starting with 4th row |
LIMIT count OFFSET offset | LIMIT 5 OFFSET 0 | Select 5 rows starting with 1st row |
Note that row numbering starts at 0, hence LIMIT 0, 5 is equivalent to LIMIT 5.
The limit applies to the number of rows returned by the database, not the number of raw samples found.
SELECT entity, AVG(value)
FROM "m-1"
GROUP BY entity
ORDER BY AVG(value) DESC
LIMIT 1
The above query retrieves all records for the 'm-1' metric, even though it returns only 1 record as instructed by the LIMIT clause.
Inline Views
Inline view is a subquery specified in the FROM clause instead of a table.
-- parent (or outer) query
SELECT expr FROM (
-- subquery (or inner / nested query)
SELECT expr ...
)
The subquery defines a virtual table to be processed by the parent query. The virtual table can be assigned an alias.
SELECT tent.env AS environment, MAX(tent.avg_val) AS max_entity
FROM (
-- subquery acting as virtual table
SELECT entity, entity.tags.environment AS env, avg(value) AS avg_val
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_DAY
GROUP BY entity
) tent
GROUP BY tent.env
| environment | max_entity |
|-------------|------------|
| prod | 15.402 |
| test | 42.601 |
The built-in columns such as entity or datetime must be listed without table prefix to be accessible in the parent query.
SELECT entity, datetime, max_val
FROM (
-- rename table prefix using alias
SELECT td.entity AS "entity", td.datetime AS "datetime", MAX(td.value) AS max_val
FROM "disk_used" td
WHERE td.entity IN ('nurswgvml006', 'nurswgvml007') AND
td.datetime BETWEEN '2019-03-29T00:00:00Z' AND '2019-03-29T00:05:00Z'
GROUP BY td.entity, PERIOD(3 MINUTE)
)
The subquery can expose columns only of numeric and text data types.
The example below calculates hourly maximum from which the parent query computes a daily average (average hourly maximum).
SELECT datetime, AVG(value) AS "daily_average"
FROM (
SELECT datetime, MAX(value) AS "value"
FROM "mpstat.cpu_busy" WHERE datetime >= CURRENT_WEEK
GROUP BY PERIOD(1 HOUR)
)
GROUP BY PERIOD(1 DAY)
| datetime | daily_average |
|---------------------|---------------|
| 2017-08-14 00:00:00 | 96.1 |
| 2017-08-15 00:00:00 | 96.6 |
| 2017-08-16 00:00:00 | 98.8 |
If the subquery column is based on an expression or function, rename it with an alias that can be referenced in the parent query.
MAX(value) AS "mval"
A subquery can include a nested subquery. Unlimited nested subqueries are supported.
SELECT MAX(value) FROM (
SELECT datetime, AVG(value) AS "value" FROM (
SELECT datetime, MAX(value) AS "value"
FROM "mpstat.cpu_busy" WHERE datetime >= CURRENT_WEEK
GROUP BY PERIOD(1 HOUR)
)
GROUP BY PERIOD(1 DAY)
)
| max(value) |
|------------|
| 98.8 |
An inline view can contain subqueries that join multiple tables.
SELECT datetime, MAX(value) AS "5-min Peak" FROM (
SELECT datetime, AVG(t1.value * t2.value) AS "value"
FROM "cpu_allocated_units" t1
JOIN "cpu_used_percent" t2
WHERE datetime >= PREVIOUS_HOUR
GROUP BY PERIOD(5 MINUTE)
)
GROUP BY PERIOD (1 HOUR)
If the SELECT statement in the outer query returns all columns, the inline SELECT must return specific columns.
SELECT * FROM (
SELECT datetime, t1.entity e1, -- SELECT * not allowed
...
) WHERE e1 IS NOT NULL
ORDER BY datetime DESC
Joins
The JOIN clause merges records from multiple tables. The database implements inner and outer joins.
Rows returned by an inner join contain equal values for joined columns.
Rows returned by an outer join contain equal or
nullvalues for joined columns.
JOIN Example
Metric m_1 records:
| m_1.datetime | m_1.value | m_1.entity |
|------------------|------------|------------|
| 2018-03-15 18:00 | 1.0 | e_1 |
| 2018-03-15 18:05 | 3.0 | e_1 |
Metric m_2 records:
| m_2.datetime | m_2.value | m_2.entity |
|------------------|------------|------------|
| 2018-03-15 18:01 | 2.0 | e_1 |
| 2018-03-15 18:05 | 4.0 | e_1 |
| 2018-03-15 18:10 | 6.0 | e_1 |
- Inner Join Query
SELECT m_1.datetime, m_2.datetime, m_1.value, m_2.value
FROM m_1
JOIN m_2
/* ON m_1.time = m_2.time
AND m_1.entity = m_2.entity
AND m_1.tags = m_2.tags */
WHERE datetime BETWEEN '2018-03-15 18:00:00' AND '2018-03-15 18:15:00'
| m_1.datetime | m_2.datetime | m_1.value | m_2.value |
|-------------------|-------------------|------------|-----------|
| 2018-03-15 18:05 | 2018-03-15 18:05 | 3.0 | 4.0 |
- Outer Join Query
SELECT m_1.datetime, m_2.datetime, m_1.value, m_2.value
FROM m_1
OUTER JOIN m_2
/* ON m_1.time = m_2.time
AND m_1.entity = m_2.entity
AND m_1.tags = m_2.tags */
WHERE datetime BETWEEN '2018-03-15 18:00:00' AND '2018-03-15 18:15:00'
| m_1.datetime | m_2.datetime | m_1.value | m_2.value |
|-------------------|-------------------|------------|-----------|
| 2018-03-15 18:00 | null | 1.0 | null |
| null | 2018-03-15 18:01 | null | 2.0 |
| 2018-03-15 18:05 | 2018-03-15 18:05 | 3.0 | 4.0 |
| null | 2018-03-15 18:10 | null | 6.0 |
JOIN Syntax
The syntax follows the SQL-92 notation for enumerating the compared columns.
FROM tbl t1
JOIN tbl t2
ON t1.time = t2.time
AND t1.entity = t2.entity
AND t1.tags = t2.tags
The ON condition can compare only the predefined columns: entity, time, datetime, and tags. Since the virtual tables contain the same predefined columns, the ON condition is optional and can be omitted.
| Compact Syntax | SQL-92 Syntax |
|---|---|
FROM tbl_1 t1JOIN tbl_2 t2 | FROM tbl_1 t1 JOIN tbl t2ON t1.time = t2.timeAND t1.entity = t2.entity AND t1.tags = t2.tags |
FROM tbl_1 t1FULL OUTER JOIN tbl_2 t2 | FROM tbl_1 t1 FULL OUTER JOIN tbl_2 t2ON t1.time = t2.timeAND t1.entity = t2.entity AND t1.tags = t2.tags |
The ON condition can be modified with the USING entity instruction in which case series tags are ignored, and records are joined on entity and time columns instead.
| Compact Syntax | SQL-92 Syntax |
|---|---|
FROM tbl_1 t1JOIN USING entity tbl_2 t2 | FROM tbl_1 t1 JOIN tbl_2 t2ON t1.time = t2.timeAND t1.entity = t2.entity |
FROM tbl_1 t1FULL OUTER JOIN USING entity tbl_2 t2 | FROM tbl_1 t1 FULL OUTER JOIN tbl_2 t2ON t1.time = t2.timeAND t1.entity = t2.entity |
Note
Self-joins (table is merged with itself) is not supported.
JOIN Results
To disambiguate column references in the join query, use qualified column names.
SELECT table_1.entity ... FROM table_1 t1
SELECT t1.entity ... FROM table_1 t1
The SELECT * and SELECT {table_name}.* expressions in join queries include qualified column names such as t1.datetime.
In addition to default columns, the JOIN query results include datetime and time columns containing a row timestamp calculated as COALESCE(t1.datetime, t2.datetime, ...).
SELECT datetime, m_1.datetime, m_2.datetime, m_1.value, m_2.value
FROM m_1
OUTER JOIN m_2
WHERE datetime BETWEEN '2018-03-15 18:00:00' AND '2018-03-15 18:15:00'
| datetime | m_1.datetime | m_2.datetime | m_1.value | m_2.value |
|-------------------|-------------------|-------------------|------------|-----------|
| 2018-03-15 18:00 | 2018-03-15 18:00 | null | 1.0 | null |
| 2018-03-15 18:01 | null | 2018-03-15 18:01 | null | 2.0 |
| 2018-03-15 18:05 | 2018-03-15 18:05 | 2018-03-15 18:05 | 3.0 | 4.0 |
| 2018-03-15 18:10 | null | 2018-03-15 18:10 | null | 6.0 |
JOIN Filtering
The WHERE filter is applied before the JOIN operation.
SELECT t1.datetime, t1.entity, t1.value, t2.datetime, t2.entity, t2.value, t2.tags
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "df.disk_used" t2
WHERE datetime BETWEEN '2018-03-09T07:07:00Z' AND '2018-03-09T07:08:00Z'
AND t1.entity = 'nurswghbs001'
Note that the t1.entity column below contains rows with null values even though this column is checked in the WHERE condition. In this example, null values are created at the OUTER JOIN stage.
| t1.datetime | t1.entity | t1.value | t2.datetime | t2.entity | t2.value | t2.tags |
|-----------------------|---------------|-----------|-----------------------|---------------|-----------|----------------------------------------|
| 2018-03-09T07:07:05Z | nurswghbs001 | 4.4 | null | null | null | null |
| null | null | null | 2018-03-09T07:07:42Z | nurswghbs001 | 248909.0 | file_system=/dev/md2;mount_point=/ |
Inner JOIN
The JOIN clause allows merging records in multiple tables for the same entity into one result set.
If the timestamps for joined metrics are identical, the JOIN operation merges rows for all the detailed records.
| datetime | entity | t1.value | t2.value | t3.value |
|----------------------|--------------|---------:|---------:|---------:|
| 2017-06-16T13:00:01Z | nurswgvml006 | 13.3 | 21.0 | 2.9 |
| 2017-06-16T13:00:17Z | nurswgvml006 | 1.0 | 2.0 | 13.0 |
| 2017-06-16T13:00:33Z | nurswgvml006 | 0.0 | 1.0 | 0.0 |
As in the example above, the cpu_system, cpu_user, cpu_iowait metrics are recorded and inserted with the same time.
datetime d:2017-06-16T13:00:01Z e:nurswgvml006 m:mpstat.cpu_system=13.3 m.mpstat.cpu_user=21.0 m:mpstat.cpu_iowait=2.9
datetime d:2017-06-16T13:00:17Z e:nurswgvml006 m:mpstat.cpu_system=1.0 m.mpstat.cpu_user=2.0 m:mpstat.cpu_iowait=13.0
datetime d:2017-06-16T13:00:33Z e:nurswgvml006 m:mpstat.cpu_system=0.0 m.mpstat.cpu_user=1.0 m:mpstat.cpu_iowait=0.0
However, when merging independent metrics, JOIN results can contain only rows with identical times.
SELECT t1.datetime, t1.entity, t1.value AS cpu, t2.value AS mem
FROM "mpstat.cpu_busy" t1
JOIN "meminfo.memfree" t2
WHERE t1.datetime >= '2017-06-16T13:00:00Z' AND t1.datetime < '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
The result contains only 2 records out of 75 total. This is because for JOIN to merge detailed records from multiple metrics into one row, the records must have the same time.
| datetime | entity | cpu | mem |
|----------------------|--------------|-----:|--------:|
| 2017-06-16T13:02:57Z | nurswgvml006 | 16.0 | 74588.0 |
| 2017-06-16T13:07:17Z | nurswgvml006 | 16.0 | 73232.0 |
To join irregular series, use GROUP BY PERIOD or WITH INTERPOLATE clauses to equalize the timestamps.
SELECT t1.entity, t1.datetime, t1.value,
t2.entity, t2.datetime, t2.value
FROM "mpstat.cpu_busy" t1
JOIN "meminfo.memfree" t2
WHERE t1.datetime BETWEEN '2017-04-08T07:01:00Z' AND '2017-04-08T07:02:00Z'
AND t1.entity = 'nurswgvml006'
WITH INTERPOLATE(15 SECOND, PREVIOUS, OUTER)
| t1.entity | t1.datetime | t1.value | t2.entity | t2.datetime | t2.value |
|--------------|----------------------|----------|--------------|----------------------|----------|
| nurswgvml006 | 2017-04-08T07:01:00Z | 5.0 | nurswgvml006 | 2017-04-08T07:01:00Z | 74804.0 |
| nurswgvml006 | 2017-04-08T07:01:15Z | 6.1 | nurswgvml006 | 2017-04-08T07:01:15Z | 71276.0 |
| nurswgvml006 | 2017-04-08T07:01:30Z | 3.0 | nurswgvml006 | 2017-04-08T07:01:30Z | 70820.0 |
| nurswgvml006 | 2017-04-08T07:01:45Z | 2.0 | nurswgvml006 | 2017-04-08T07:01:45Z | 69944.0 |
| nurswgvml006 | 2017-04-08T07:02:00Z | 10.9 | nurswgvml006 | 2017-04-08T07:02:00Z | 75928.0 |
Series with tags can be joined without enumerating all possible tag names in the JOIN condition.
SELECT t1.datetime, t1.entity, t1.value, t2.value, t1.tags.*
FROM "df.disk_used" t1
JOIN "df.disk_used_percent" t2
WHERE t1.datetime >= '2017-06-16T13:00:00Z' AND t1.datetime < '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
| datetime | entity | t1.value | t2.value | t1.tags.file_system | t1.tags.mount_point |
|----------------------|--------------|--------------|----------|---------------------------------|---------------------|
| 2017-06-16T13:00:14Z | nurswgvml006 | 1743057408.0 | 83.1 | //u113452.nurstr003/backup | /mnt/u113452 |
| 2017-06-16T13:00:29Z | nurswgvml006 | 1743057408.0 | 83.1 | //u113452.nurstr003/backup | /mnt/u113452 |
| 2017-06-16T13:00:44Z | nurswgvml006 | 1743057408.0 | 83.1 | //u113452.nurstr003/backup | /mnt/u113452 |
| 2017-06-16T13:00:59Z | nurswgvml006 | 1743057408.0 | 83.1 | //u113452.nurstr003/backup | /mnt/u113452 |
OUTER JOIN
To combine all records from joined tables, use FULL OUTER JOIN (synonyms OUTER JOIN or FULL JOIN), which returns rows with equal time, entity, and tags as well as rows from one table for which no rows from the other table satisfy the join condition.
SELECT t1.datetime, t1.entity, t1.value AS cpu,
t2.datetime, t2.entity, t2.value AS mem
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
-- FULL JOIN "meminfo.memfree" t2
-- OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime >= '2017-06-16T13:00:00Z' AND t1.datetime < '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
FULL OUTER JOIN on detailed records, without period aggregation, produces rows with NULL columns for series with any recorded value at the specified time.
| t1.datetime | t1.entity | cpu | t2.datetime | t2.entity | mem |
|----------------------|--------------|------|----------------------|--------------|-------|
| 2017-06-16T13:00:01Z | nurswgvml006 | 37 | null | null | null |
| null | null | null | 2017-06-16T13:00:12Z | nurswgvml006 | 67932 |
| 2017-06-16T13:00:17Z | nurswgvml006 | 16 | null | null | null |
| null | null | null | 2017-06-16T13:00:27Z | nurswgvml006 | 73620 |
To regularize the merged series in join queries, apply interpolation or period aggregation using an aggregate function.
- Interpolation
SELECT t1.datetime, t1.entity, t1.value AS cpu,
t2.datetime, t2.entity, t2.value AS mem
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime >= '2017-06-16T13:00:00Z' AND t1.datetime < '2017-06-16T13:10:00Z'
AND t1.entity = 'nurswgvml006'
WITH INTERPOLATE(15 SECOND, LINEAR, OUTER)
| t1.datetime | t1.entity | cpu | t2.datetime | t2.entity | mem |
|----------------------|--------------|------|----------------------|--------------|---------|
| 2017-06-16T13:00:00Z | nurswgvml006 | 34.9 | 2017-06-16T13:00:00Z | nurswgvml006 | 69903.2 |
| 2017-06-16T13:00:15Z | nurswgvml006 | 18.6 | 2017-06-16T13:00:15Z | nurswgvml006 | 69069.6 |
| 2017-06-16T13:00:30Z | nurswgvml006 | 3.8 | 2017-06-16T13:00:30Z | nurswgvml006 | 74041.6 |
- Aggregation
The PERIOD() column (without the preceding table name) calculates the start of the period based on the datetime column.
SELECT datetime, ISNULL(t1.entity, t2.entity) AS server,
AVG(t1.value) AS avg_cpu, AVG(t2.value) AS avg_mem
FROM "mpstat.cpu_busy" t1
FULL OUTER JOIN "meminfo.memfree" t2
WHERE t1.datetime >= '2017-06-16T13:00:00Z' AND t1.datetime < '2017-06-16T13:10:00Z'
GROUP BY PERIOD(1 MINUTE), server
ORDER BY datetime
| datetime | server | avg_cpu | avg_mem |
|----------------------|--------------|---------|----------|
| 2017-06-16T13:00:00Z | nurswgvml006 | 15.8 | 73147.0 |
| 2017-06-16T13:00:00Z | nurswgvml007 | 9.8 | 259757.0 |
| 2017-06-16T13:01:00Z | nurswgvml006 | 2.8 | 69925.0 |
| 2017-06-16T13:01:00Z | nurswgvml007 | 3.5 | 252451.0 |
Note
Records returned by a JOIN USING entity condition include series with a last insert date greater than the start date specified in the query.
JOIN with atsd_series table
When metrics selected from the atsd_series table are joined with metrics referenced in the query, each atsd_series metric is joined with a referenced metric separately.
SELECT base.entity, base.metric, base.datetime, base.value, t1.value AS "cpu_sys"
FROM atsd_series base
JOIN "mpstat.cpu_system" t1
WHERE base.metric IN ('mpstat.cpu_busy', 'mpstat.cpu_user')
AND base.entity = 'nurswgvml007'
AND base.datetime > PREVIOUS_MINUTE
ORDER BY base.datetime
| base.entity | base.metric | base.datetime | base.value | cpu_sys |
|--------------|-------------|----------------------|------------|---------|
| nurswgvml007 | cpu_busy | 2017-04-07T15:04:08Z | 5.0 | 2.0 | cpu_busy JOIN cpu_system
| nurswgvml007 | cpu_busy | 2017-04-07T15:04:24Z | 5.1 | 2.0 | cpu_busy JOIN cpu_system
...
| nurswgvml007 | cpu_user | 2017-04-07T15:04:08Z | 2.0 | 2.0 | cpu_user JOIN cpu_system
| nurswgvml007 | cpu_user | 2017-04-07T15:04:24Z | 3.1 | 2.0 | cpu_user JOIN cpu_system
...
Functions
Aggregate Functions
The following functions aggregate values in a column by producing a single value from a list of values appearing in a column.
|----------------|----------------|----------------|----------------|
| AVG | CORREL | COUNT | COUNTER |
| COVAR | DELTA | FIRST | LAST |
| MAX | MAX_VALUE_TIME | MEDIAN | MEDIAN_ABS_DEV |
| MIN | MIN_VALUE_TIME | PERCENTILE | SUM |
| STDDEV | WAVG | WTAVG | |
|----------------|----------------|----------------|----------------|
Supported Arguments
- All functions accept a numeric expression or a numeric column as an argument, for example
AVG(value)orAVG(t1.value + t2.value). COUNTfunction accepts any expression, including*, for exampleCOUNT(*)orCOUNT(datetime).- In addition to numbers, the
MIN,MAX,FIRST, andLASTaggregate functions accept theTIMESTAMPdata type, for exampleMAX(datetime).
Returned Data Types
- Functions
COUNT,MIN_VALUE_TIMEandMAX_VALUE_TIMEreturnBIGINTdatatype. - The remaining functions return a value with data type depending on the argument data type:
- DECIMAL if the argument is of DECIMAL datatype.
- TIMESTAMP if the argument is of TIMESTAMP data type.
- DOUBLE if the argument data type is not DECIMAL or TIMESTAMP.
Implementation Notes
NULLandNaNvalues are ignored by aggregate functions.- If the aggregate function of
DOUBLEdatatype cannot find a single value other thanNULLorNaN, it returnsNaN. - If the aggregate function of
BIGINTdatatype cannot find a single value other thanNULLorNaN, it returnsNULL. - Nested aggregate functions such as
AVG(MAX(value))are not supported.
SELECT entity, AVG(value), MAX(value), COUNT(*), PERCENTILE(80, value)
FROM "mpstat.cpu_busy"
WHERE datetime > current_hour
GROUP BY entity
| entity | AVG(value) | MAX(value) | COUNT(*) | PERCENTILE(80,value) |
|--------------|------------|------------|----------|----------------------|
| nurswghbs001 | 20.3 | 48.0 | 49.0 | 22.8 |
COUNT
The COUNT(*) function returns the number of rows in the result set, whereas the COUNT(expr) returns the number of rows where the expression expr is not NULL or NaN.
PERCENTILE
The PERCENTILE function calculates the number which is greater than the specified percentage of values in the given period.
The function accepts percentile parameter within the [0, 100] range as the first argument and a numeric expression as the second argument, for example PERCENTILE(99.9, value).
PERCENTILE(100, value)equalsMAX(value)PERCENTILE(0, value)equalsMIN(value).
The function implements the R6 method as described in the NIST Engineering Handbook, Section 2.6.2, which uses N+1 as the array size (N is the number of samples in the period) and performs linear interpolation between consecutive values.
PRODUCT
PRODUCT is an aggregate function that multiplies the values of numeric expression expr and returns the product.
FIRST
FIRST is an aggregate function that returns the value of the first sample (or the value of expression expr for the first row) in the set which is ordered by time in ascending order.
Note that
FIRST_VALUEis an analytical function.
LAST
LAST is an aggregate function that returns the value of the last sample (or the value of expression expr for the last row) in the set which is ordered by time in ascending order.
MIN_VALUE_TIME
The MIN_VALUE_TIME function returns Unix time in milliseconds (BIGINT datatype) of the first occurrence of the minimum value.
MAX_VALUE_TIME
The MAX_VALUE_TIME function returns Unix time in milliseconds (BIGINT datatype) of the first occurrence of the maximum value.
STDDEV
The STDDEV function calculates standard deviation as the square root of sum of squared deviations divided by n - 1 (sample size).

An optional second argument controls whether the variance is divided by n - 1 (sample) or n (population).
STDDEV(expr [, SAMPLE | POPULATION])
MEDIAN_ABS_DEV
The MEDIAN_ABS_DEV function returns median absolute deviation which represents a robust estimate of the variance.
median(ABS(expr - median(expr))
CORREL
The CORREL correlation function accepts two numeric expressions as arguments (or two value columns in a JOIN query) and calculates the Pearson correlation coefficient between them.
If one of the variables is constant (its standard deviation is 0), the
CORRELfunction returnsNaN.
SELECT tA.entity,
CORREL(tA.value, tB.value) AS "CORR-AB",
COVAR(tA.value, tB.value) AS "COVAR-AB"
FROM "mpstat.cpu_user" tA JOIN "mpstat.cpu_system" tB
WHERE tA.datetime BETWEEN '2019-02-18T10:00:00Z' AND '2019-02-18T10:30:00Z' EXCL
GROUP BY tA.entity
| tA.entity | CORR-AB | COVAR-AB |
|--------------|---------|----------|
| nurswgvml007 | 0.37 | 9.46 |
| nurswgvml006 | 0.62 | 0.62 |
| nurswgvml010 | 0.86 | 3.07 |
| nurswgvml501 | 0.34 | 1.05 |
| nurswgvml502 | 0.43 | 0.26 |
| nurswgvml301 | 0.18 | 0.14 |
COVAR
The COVAR function calculates the covariance between the pair of variables.

An optional second argument controls whether the covariance is divided by n - 1 (sample) or n (population).
COVAR(expr1, expr2 [, SAMPLE | POPULATION])
REGR_INTERCEPT
The REGR_INTERCEPT and REGR_SLOPE functions calculate linear coefficients based on the ordinary-least-squares method.
y is the dependent variable, and x is the independent variable.
REGR_INTERCEPT(y, x)
REGR_SLOPE(y, x)
SELECT entity, date_format(LAST(time), 'yyyy-MM-dd HH:mm:ss') AS dt,
FIRST(value) AS first_val, LAST(value) AS last_val,
REGR_INTERCEPT(value, time) + REGR_SLOPE(value, time)*(LAST(time)+12*60*60000) AS exp_value
FROM "df.disk_used_percent"
WHERE datetime > NOW - 12*HOUR
AND entity LIKE 'nurswgvml%' AND tags.mount_point = '/'
GROUP BY entity, tags
| entity | dt | first_val | last_val | exp_value |
|--------------|---------------------|-----------|----------|-----------|
| nurswgvml007 | 2019-11-29 13:10:36 | 67.27 | 69.61 | 71.01 |
| nurswgvml010 | 2019-11-29 13:10:36 | 58.20 | 60.20 | 58.51 |
| nurswgvml501 | 2019-11-29 13:10:34 | 31.63 | 31.64 | 31.65 |
| nurswgvml502 | 2019-11-29 13:10:38 | 69.33 | 69.34 | 69.39 |
| nurswgvml301 | 2019-11-29 13:10:38 | 39.28 | 39.29 | 39.29 |
| nurswgvml006 | 2019-11-29 13:10:34 | 47.15 | 47.21 | 47.27 |
The functions can be used as aggregate and analytical functions.
Date Functions
DATE_FORMAT
The date_format function converts Unix time in milliseconds to a string according to the specified time format in the optional time zone.
date_format(bigint milliseconds[, varchar time_format[, varchar time_zone]])
If the time_format argument is not provided, ISO format is applied.
The time_zone parameter accepts GMT offset in the format of GMT-hh:mm or a time zone name to format dates in a time zone other than the database time zone.
The time_zone parameter can be set to AUTO in which case the date is formatted with an entity-specific time zone. If an entity time zone is not defined, a metric-specific time zone is used instead. If neither an entity-specific nor metric-specific time zone is set, the database time zone is applied.
Examples:
date_format(time)date_format(max_value_time(value))date_format(time, 'yyyy-MM-dd HH:mm:ss')date_format(time, 'yyyy-MM-dd HH:mm:ss', 'PST')date_format(time, 'yyyy-MM-dd HH:mm:ss', 'GMT-08:00')date_format(time, 'yyyy-MM-dd HH:mm:ss ZZ', 'PDT')date_format(time, 'yyyy-MM-dd HH:mm:ss', entity.timeZone)date_format(time, 'yyyy-MM-dd HH:mm:ss', AUTO)
SELECT entity, datetime, metric.timeZone AS "Metric TZ", entity.timeZone AS "Entity TZ",
date_format(time) AS "default",
date_format(time, 'yyyy-MM-ddTHH:mm:ssZZ') AS "ISO Format",
date_format(time, 'yyyy-MM-dd HH:mm:ss') AS "Local Database",
date_format(time, 'yyyy-MM-dd HH:mm:ss', 'GMT-08:00') AS "GMT Offset",
date_format(time, 'yyyy-MM-dd HH:mm:ss', 'PDT') AS "PDT",
date_format(time, 'yyyy-MM-dd HH:mm:ssZZ', 'PDT') AS " PDT t/z",
date_format(time, 'yyyy-MM-dd HH:mm:ssZZ', AUTO) AS "AUTO: CST" -- nurswgvml006 is in CST
FROM "mpstat.cpu_busy"
WHERE datetime >= NOW - 5*MINUTE
AND entity = 'nurswgvml006'
LIMIT 1
| entity | datetime | Metric TZ | Entity TZ | default | ISO Format | Local Database | GMT Offset | PDT | PDT t/z | AUTO: CST |
|--------------|--------------------------|------------|-------------|--------------------------|------------------------|-----------------------|---------------------|---------------------|---------------------------|---------------------------|
| nurswgvml006 | 2017-04-06T11:03:19.000Z | US/Eastern | US/Mountain | 2017-04-06T11:03:19.000Z | 2017-04-06T11:03:19Z | 2017-04-06 11:03:19 | 2017-04-06 03:03:19 | 2017-04-06 04:03:19 | 2017-04-06 04:03:19-07:00 | 2017-04-06 05:03:19-06:00 |
| format | date_format value |
|-----------------------------------------------------------|----------------------------|
| time | 1468411675000 |
| date_format(time) | 2017-07-13T12:07:55.000Z |
| date_format(time+60000) | 2017-07-13T12:08:55.000Z |
| date_format(time,'yyyy-MM-ddTHH:mm:ss.SSSZ','UTC') | 2017-07-13T12:07:55.000Z |
| date_format(time,'yyyy-MM-dd HH:mm:ss') | 2017-07-13 12:07:55 |
| date_format(time,'yyyy-MM-dd HH:mm:ss','PST') | 2017-07-13 05:07:55 |
| date_format(time,'yyyy-MM-dd HH:mm:ss','GMT-08:00') | 2017-07-13 04:07:55 |
| date_format(time,'yyyy-MM-dd HH:mm:ssZ','PST') | 2017-07-13 05:07:55-0700 |
| date_format(time,'yyyy-MM-dd HH:mm:ssZZ','PST') | 2017-07-13 05:07:55-07:00 |
The date_format function can be used to print period start and end times.
SELECT datetime AS period_start, date_format(time+60*60000) AS period_end, AVG(value)
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime >= CURRENT_DAY
GROUP BY PERIOD(1 HOUR)
| period_start | period_end | AVG(value) |
|----------------------|----------------------|------------|
| 2017-08-25T00:00:00Z | 2017-08-25T01:00:00Z | 7.7 |
| 2017-08-25T01:00:00Z | 2017-08-25T02:00:00Z | 8.2 |
| 2017-08-25T02:00:00Z | 2017-08-25T03:00:00Z | 6.7 |
In addition to formatting, the date_format function can be used in the WHERE, GROUP BY, and HAVING clauses to filter and group dates by month, day, or hour.
SELECT date_format(time, 'eee'), AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= CURRENT_MONTH
GROUP BY date_format(time, 'eee')
ORDER BY 2 DESC
| date_format(time,'eee') | AVG(value) |
|-------------------------|------------|
| Mon | 31.9 |
| Wed | 31.8 |
| Sun | 31.4 |
| Tue | 31.2 |
| Thu | 29.6 |
| Sat | 29.6 |
| Fri | 29.3 |
Refer to diurnal query examples.
By retrieving date parts from the time column, the records can be filtered by calendar.
The query below includes samples recorded only during daytime hours (from 08:00 till 17:59) on weekdays (Monday till Friday).
SELECT datetime, date_format(time, 'eee') AS "day of week", avg(value), count(value)
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime >= previous_week AND datetime < current_week
AND HOUR(time) BETWEEN 8 AND 17
AND is_weekday(time, 'USA')
GROUP BY PERIOD(1 hour)
| datetime | day of week | avg(value) | count(value) |
|----------------------|--------------|-------------|--------------|
| 2018-03-12 08:00:00 | Mon | 14.535 | 223 |
| 2018-03-12 09:00:00 | Mon | 12.626 | 225 |
| 2018-03-12 10:00:00 | Mon | 12.114 | 225 |
| 2018-03-12 11:00:00 | Mon | 11.314 | 225 |
...
DATE_PARSE
The date_parse function parses the date and time string into Unix time with millisecond precision.
date_parse(varchar datetime [, varchar time_format [, varchar time_zone]])
- The default
time_formatis ISO format:yyyy-MM-ddTHH:mm:ss.SSSZZ. See supported pattern letters on Date and Time Letter Patterns. - The default
time_zoneis the database time zone.
/* Parse date using the default ISO format.*/
date_parse('2017-03-31T12:36:03.283Z')
/* Parse date using the ISO format, without milliseconds */
date_parse('2017-03-31T12:36:03Z', 'yyyy-MM-ddTHH:mm:ssZZ')
/* Parse date using the database time zone. */
date_parse('31.03.2017 12:36:03.283', 'dd.MM.yyyy HH:mm:ss.SSS')
/* Parse date using the offset specified in the timestamp string. */
date_parse('31.03.2017 12:36:03.283 -08:00', 'dd.MM.yyyy HH:mm:ss.SSS ZZ')
/* Parse date using the time zone specified in the timestamp string. */
date_parse('31.03.2017 12:36:03.283 Europe/Berlin', 'dd.MM.yyyy HH:mm:ss.SSS ZZZ')
/* Parse date using the time zone provided as the third argument. */
date_parse('31.01.2017 12:36:03.283', 'dd.MM.yyyy HH:mm:ss.SSS', 'Europe/Berlin')
/* Parse date using the UTC offset provided as the third argument. */
date_parse('31.01.2017 12:36:03.283', 'dd.MM.yyyy HH:mm:ss.SSS', '+01:00')
/* Time zone (offset) specified in the timestamp must be the same as provided in the third argument. */
date_parse('31.01.2017 12:36:03.283 Europe/Berlin', 'dd.MM.yyyy HH:mm:ss.SSS ZZZ', 'Europe/Berlin')
DATE_ROUND
The date_round function rounds the input date to the start of the containing calendar period. The date can be specified as literal date, Unix time in milliseconds or a calendar expression.
date_round(varchar date | bigint time, int count varchar unit)
date_round(calendar_expression, int count varchar unit)
-- assuming current time is 15:39, the interval is [15:35, 15:40)
WHERE datetime >= date_round(now, 5 MINUTE) AND datetime < date_round(now + 5*minute, 5 MINUTE)
DATEADD
The DATEADD function performs calendar arithmetic by adding or subtracting an interval to the specified time column and returns the modified value in the same datatype as the input column.
- The interval is specified as a product of
datePartanddateCount. For example, an interval of 3 days is set with argumentsDAYand3. - The
datePartargument can beYEAR,QUARTER,MONTH,WEEK,DAY,HOUR,MINUTE, orSECOND. - To subtract an interval, set
dateCountto a negative integer. - The column name or expression to which the interval is added is specified as the third argument. It can refer to a column name, such as
datetimeortime, or an expression returning Unix time measured in milliseconds, or a date string in ISO format. - An optional time zone name can be specified as the last argument to perform calendar calculations in a user-defined time zone. By the default, the database time zone is used.
DATEADD(varchar datePart, integer dateCount, bigint time | varchar datetime [, varchar timeZone])
SELECT datetime, DATEADD(DAY, -6, datetime) AS "week_ago"
FROM "mpstat.cpu_busy"
LIMIT 3
| datetime | week_ago |
|-----------------------|----------------------|
| 2013-06-17T07:29:04Z | 2013-06-11T07:29:04Z |
| 2013-06-17T07:29:20Z | 2013-06-11T07:29:20Z |
| 2013-06-17T07:29:36Z | 2013-06-11T07:29:36Z |
ENDTIME
The ENDTIME function evaluates the specified calendar keywords as well as literal dates in the user-defined time zone, which can be different from the database time zone.
ENDTIME(calendarExpression, varchar timeZone)
SELECT value, datetime,
date_format(time, 'yyyy-MM-ddTHH:mm:ssz', 'UTC') AS "UTC_datetime",
date_format(time, 'yyyy-MM-ddTHH:mm:ssz', 'US/Pacific') AS "PST_datetime"
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
-- Select data between 0h:0m:0s of the previous day and 0h:0m:0s of the current day according to PST time zone
-- By default BETWEEN is inclusive of upper range. Use BETWEEN a AND b EXCL to override.
AND datetime BETWEEN ENDTIME(YESTERDAY, 'US/Pacific') AND ENDTIME(CURRENT_DAY, 'US/Pacific')
ORDER BY datetime
| value | datetime | UTC_datetime | PST_datetime |
|-------|----------------------|------------------------|------------------------|
| 6.86 | 2017-06-16T07:00:05Z | 2017-06-16T07:00:05UTC | 2017-06-16T00:00:05PDT |
| 6.06 | 2017-06-16T07:00:21Z | 2017-06-16T07:00:21UTC | 2017-06-16T00:00:21PDT |
....
| 3.03 | 2017-06-17T06:59:29Z | 2017-06-17T06:59:29UTC | 2017-06-16T23:59:29PDT |
| 2.97 | 2017-06-17T06:59:45Z | 2017-06-17T06:59:45UTC | 2017-06-16T23:59:45PDT |
The literal dates can be specified in one of the following formats: yyyy-MM-dd HH:mm:ss, yyyy-MM-dd HH:mm, and yyyy-MM-dd.
INTERVAL_NUMBER
The INTERVAL_NUMBER function can be referenced in the SELECT expression.
It returns an index, starting with 1, of the current time interval in queries selecting multiple intervals using a datetime OR condition or datetime subquery.
SELECT datetime, count(*), INTERVAL_NUMBER()
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND (datetime BETWEEN current_day AND next_day
OR datetime BETWEEN current_day-1*WEEK AND next_day-1*WEEK)
GROUP BY PERIOD(1 DAY)
| datetime | count(*) | interval_number() |
|----------------------|----------|-------------------|
| 2017-04-09T00:00:00Z | 5393 | 1 |
| 2017-04-16T00:00:00Z | 5191 | 2 |
EXTRACT
The function returns an integer value corresponding to the specified calendar part (component) of the provided date.
EXTRACT(datepart FROM datetime | time | datetime expression [, timezone])
The datepart argument can be YEAR, QUARTER, MONTH, DAY, HOUR, MINUTE, or SECOND.
The evaluation is based on the database time zone unless a custom time zone is specified. The date argument can refer to the time or datetime columns and calendar keywords and expressions..
SELECT datetime,
EXTRACT(year FROM datetime) AS "year",
EXTRACT(quarter FROM datetime) AS "quarter",
EXTRACT(month FROM datetime) AS "month",
EXTRACT(day FROM datetime) AS "day",
EXTRACT(hour FROM datetime) AS "hour",
EXTRACT(minute FROM datetime) AS "minute",
EXTRACT(second FROM datetime) AS "second",
EXTRACT(day FROM now - 1*DAY) AS "prev_day",
EXTRACT(month FROM now + 1*MONTH) AS "next_month",
date_format(time, 'yyyy-MM-dd HH:mm:ss', 'Asia/Seoul') AS "date_local",
EXTRACT(day FROM datetime, 'Asia/Seoul') AS "day_local"
FROM "cpu_busy"
WHERE datetime >= '2018-08-05T21:00:00Z'
LIMIT 1
| datetime | year | quarter | month | day | hour | minute | second | prev_day | next_month | date_local | day_local |
|----------------------|------|---------|-------|-----|------|--------|--------|----------|------------|---------------------|-----------|
| 2018-08-05T21:00:04Z | 2018 | 3 | 8 | 5 | 21 | 0 | 4 | 6 | 9 | 2018-08-06 06:00:04 | 6 |
SECOND
The second function returns the current seconds in the provided date.
SECOND (datetime | time | datetime expression)
MINUTE
The minute function returns the current minutes in the provided date.
MINUTE (datetime | time | datetime expression [, timezone])
HOUR
The hour function returns the current hour of the day (0 - 23) in the provided date.
HOUR (datetime | time | datetime expression [, timezone])
DAY
The day function returns the current day of month in the provided date.
DAY (datetime | time | datetime expression [, timezone])
DAYOFWEEK
The dayofweek function returns the current day of week (1-7, starting with Monday) in the provided date.
DAYOFWEEK (datetime | time | datetime expression [, timezone])
MONTH
The month function returns the current month (1-12) in the provided date.
MONTH (datetime | time | datetime expression [, timezone])
QUARTER
The quarter function returns the current quarter of the year in the provided date.
QUARTER (datetime | time | datetime expression [, timezone])
YEAR
The year function returns the current year in the provided date.
YEAR (datetime | time | datetime expression [, timezone])
CURRENT_TIMESTAMP
The CURRENT_TIMESTAMP function returns current database time in ISO format. The function is analogous to the NOW functions which returns current database time (Unix time, millisecond precision).
SELECT CURRENT_TIMESTAMP
SELECT entity, datetime, value
FROM "mpstat.cpu_busy"
-- same as datetime > NOW - 1 * DAY
WHERE datetime > CURRENT_TIMESTAMP - 1 * DAY
DBTIMEZONE
The DBTIMEZONE function returns the current database time zone name or offset.
SELECT DBTIMEZONE
-- returns GMT0
IS_WORKDAY
The IS_WORKDAY function returns true if the given date is a working day based on holiday exceptions in the specified Workday Calendar, which is typically the three-letter country code such as USA.
IS_WORKDAY(datetime | time | datetime expression [, calendar_key [, timezone]])
Notes:
- To determine if the date argument is a working day, the function converts the date to
yyyy-MM-ddformat in the database or user-definedtimezoneand checks if the date is present in the specified Workday Calendar exception list. For example, if the date argument is2018-07-04T00:00:00Zand the calendar key isUSA, the function checks the file/opt/atsd/atsd/conf/calendars/usa.jsonfor the list of observed holidays. The date2018-07-04matches the Fourth of July holiday. Thus, the function returnsfalse, though the date is a Wednesday. - The function raises an error if the calendar is not found or no exceptions are found for the given year (
2018in the above case).
SELECT date_format(datetime, 'yyyy-MM-dd') AS "Date",
date_format(datetime, 'eee') AS "Day of Week",
date_format(datetime, 'u') AS "DoW Number",
is_workday(datetime, 'USA') AS "USA Work Day",
is_workday(datetime, 'ISR') AS "Israel Work Day"
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2018-07-02' AND '2018-07-09'
GROUP BY PERIOD(1 day)
ORDER BY datetime
| Date | Day of Week | DoW Number | USA Work Day | Israel Work Day |
|------------|-------------|------------|--------------|-----------------|
| 2018-07-02 | Mon | 1 | true | true |
| 2018-07-03 | Tue | 2 | true | true |
| 2018-07-04 | Wed | 3 | false (!) | true | <-- 4th of July holiday observed in the USA
| 2018-07-05 | Thu | 4 | true | true |
| 2018-07-06 | Fri | 5 | true | false |
| 2018-07-07 | Sat | 6 | false | false |
| 2018-07-08 | Sun | 7 | false | true |
To check if the date argument is a working day in the local time zone, call the function with the custom time zone.
is_workday(time, 'USA', 'US/Pacific')
IS_WEEKDAY
The IS_WEEKDAY function returns true if the given date is a regular work day in the specified Workday Calendar, which is typically the three-letter country code such as USA. Weekdays are Monday to Friday in the USA and Sunday to Thursday in Israel, for example.
Unlike the IS_WORKDAY, the IS_WEEKDAY function ignores observed holidays.
IS_WEEKDAY(datetime | time | datetime expression [, calendar_key [, timezone]])
SELECT date_format(datetime, 'yyyy-MM-dd') AS "Date",
date_format(datetime, 'eee') AS "Day of Week",
date_format(datetime, 'u') AS "DoW Number",
is_workday(datetime, 'USA') AS "USA Work Day",
is_weekday(datetime, 'USA') AS "USA Week Day",
is_workday(datetime, 'ISR') AS "Israel Work Day",
is_weekday(datetime, 'ISR') AS "Israel Week Day"
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2018-05-18' AND '2018-05-30'
GROUP BY PERIOD(1 day)
ORDER BY datetime
| Date | Day of Week | DoW Number | USA Work Day | USA Week Day | Israel Work Day | Israel Week Day |
|-------------|--------------|-------------|---------------|---------------|------------------|-----------------|
| 2018-05-18 | Fri | 5 | true | true | false | false |
| 2018-05-19 | Sat | 6 | false | false | false | false |
| 2018-05-20 | Sun | 7 | false | false | false (!) | true | <-- Pentecost
| 2018-05-21 | Mon | 1 | true | true | true | true |
| 2018-05-22 | Tue | 2 | true | true | true | true |
| 2018-05-23 | Wed | 3 | true | true | true | true |
| 2018-05-24 | Thu | 4 | true | true | true | true |
| 2018-05-25 | Fri | 5 | true | true | false | false |
| 2018-05-26 | Sat | 6 | false | false | false | false |
| 2018-05-27 | Sun | 7 | false | false | true | true |
| 2018-05-28 | Mon | 1 | false (!) | true | true | true | <-- Memorial Day
| 2018-05-29 | Tue | 2 | true | true | true | true |
WORKDAY
The WORKDAY function shifts the input date by the specified number of working days. The shift is backward if the days parameter is negative. Refer to IS_WORKDAY function for working day definitions.
WORKDAY(datetime | time | datetime expression, days[, calendar_key[, timezone]])
The time part of the day remains unchanged. If the days argument is 0 and the input date is not a working day, the function returns NULL.
Example: two working days before current day.
--> July 09 (Tuesday) returns July 5th (Friday)
--> July 08 (Monday) returns July 3rd (Wednesay, because July 4th is not a working day)
WORKDAY(datetime, -2, 'usa')
SELECT value,
date_format(time, 'EEE yyyy-MMM-dd HH:mm:ss') AS base,
date_format(WORKDAY(datetime, -1, 'usa'), 'EEE yyyy-MMM-dd HH:mm:ss') as "base-1",
date_format(WORKDAY(datetime, -2, 'usa'), 'EEE yyyy-MMM-dd HH:mm:ss') as "base-2"
FROM "mpstat.cpu_busy"
WHERE datetime BETWEEN '2019-07-08 15:00:00' and '2019-07-08 15:01:00'
AND entity = 'nurswgvml007'
| value | base | base-1 | base-2 |
|---------|--------------------------|--------------------------|--------------------------|
| 63.2700 | Mon 2019-Jul-08 15:00:10 | Fri 2019-Jul-05 15:00:10 | Wed 2019-Jul-03 15:00:10 |
WEEKDAY
The function shifts the input date by the specified number of regular work days. The implementation is comparable to WORKDAY function.
WORKDAY_COUNT
The WORKDAY_COUNT function returns the number of working days between the two input dates according to the specified calendar.
WORKDAY_COUNT(datetime | time | datetime fromDate, datetime | time | datetime toDate [, calendar_key[, timezone]])
If the toDate precedes the fromDate, the difference is negative.
WITH TIMEZONE
The TIMEZONE clause overrides the default database time zone applied in period aggregation, interpolation, and date functions. The custom time zone applies to all date transformations performed by the query.
WITH = timezone
SELECT DBTIMEZONE,
date_format(time, 'yyyy-MM-dd HH:mm z') AS "period_start_default",
date_format(time, 'yyyy-MM-dd HH:mm z', 'UTC') AS "period_start_utc",
date_format(time, 'yyyy-MM-dd HH:mm z', 'US/Pacific') AS "period_start_local",
AVG(value), COUNT(value)
FROM "mpstat.cpu_busy"
WHERE datetime >= '2018-08-01' AND datetime < '2018-08-03'
-- change the default database time zone from UTC to US/Pacific
WITH TIMEZONE = 'US/Pacific'
GROUP BY PERIOD(1 DAY)
| DBTIMEZONE | period_start_default | period_start_utc | period_start_local | avg(value) | count(value) |
|-------------|-----------------------|-----------------------|-----------------------|-------------|--------------|
| Etc/UTC | 2018-08-01 00:00 PDT | 2018-08-01 07:00 UTC | 2018-08-01 00:00 PDT | 2821.5 | 48 |
| Etc/UTC | 2018-08-02 00:00 PDT | 2018-08-02 07:00 UTC | 2018-08-02 00:00 PDT | 2862.5 | 48 |
The same query in the default database time zone (UTC) produces the following results:
| DBTIMEZONE | period_start_default | period_start_utc | period_start_local | avg(value) | count(value) |
|-------------|-----------------------|-----------------------|-----------------------|-------------|--------------|
| Etc/UTC | 2018-08-01 00:00 UTC | 2018-08-01 00:00 UTC | 2018-07-31 17:00 PDT | 2807.5 | 48 |
| Etc/UTC | 2018-08-02 00:00 UTC | 2018-08-02 00:00 UTC | 2018-08-01 17:00 PDT | 2855.5 | 48 |
In case of nested queries, the TIMEZONE specified in the outer query is inherited by inner queries.
Absent the WITH TIMEZONE clause, each function must be individually programmed to account for the custom time zone. In the below example, the time zone adjustments are necessary in the date_format function, the GROUP BY PERIOD clause, and the selection interval.
SELECT DBTIMEZONE,
-- the default format must use to US/Pacific time zone, otherwise it displays UTC
date_format(time, 'yyyy-MM-dd HH:mm z') AS "period_start_default",
date_format(time, 'yyyy-MM-dd HH:mm z', 'UTC') AS "period_start_utc",
date_format(time, 'yyyy-MM-dd HH:mm z', 'US/Pacific') AS "period_start_local",
AVG(value), COUNT(value)
FROM "mpstat.cpu_busy"
-- shift the start and end date to US/Pacific time zone
WHERE datetime >= '2018-08-01T00:00:00-07:00' AND datetime < '2018-08-03T00:00:00-07:00'
-- align to day start in US/Pacific time zone
GROUP BY PERIOD(1 DAY, 'US/Pacific')
| DBTIMEZONE | period_start_default | period_start_utc | period_start_local | avg(value) | count(value) |
|-------------|-----------------------|-----------------------|-----------------------|-------------|--------------|
| Etc/UTC | 2018-08-01 07:00 UTC | 2018-08-01 07:00 UTC | 2018-08-01 00:00 PDT | 2821.5 | 48 |
| Etc/UTC | 2018-08-01 07:00 UTC | 2018-08-02 07:00 UTC | 2018-08-02 00:00 PDT | 2862.5 | 48 |
WITH WORKDAY_CALENDAR
The WORKDAY_CALENDAR clause overrides the default workday calendar applied in date functions and calendar keywords. The installed calendars are listed on the Data > Workday Calendars page.
WITH WORKDAY_CALENDAR = 'us_fin'
SELECT date_format(time, 'yyyy-MM-dd EEEE') AS dt,
IS_WORKDAY(time),
COUNT(value)
FROM "cpu_busy"
WHERE datetime >= '2019-05-03' AND datetime < '2019-05-09'
AND entity = 'nurswgvml007'
-- AND IS_WORKDAY(datetime)
WITH WORKDAY_CALENDAR = 'gbr'
GROUP BY PERIOD(1 DAY)
| dt | is_workday(time, 'gbr') | count(value) |
|----------------------|-------------------------|--------------|
| 2019-05-03 Friday | true | 5397 |
| 2019-05-04 Saturday | false | 5397 |
| 2019-05-05 Sunday | false | 5397 |
| 2019-05-06 Monday | false | 5394 | <-- May Day Bank Holiday
| 2019-05-07 Tuesday | true | 5394 |
| 2019-05-08 Wednesday | true | 5397 |
In case of nested queries, the WORKDAY_CALENDAR specified in the outer query is inherited by inner queries.
Mathematical Functions
| Function | Description |
|---|---|
ABS(num) | Absolute value of the specified number. |
CEIL(num) | Smallest integer that is greater than or equal to the specified number. |
EXP(num) | Mathematical constant e (2.718281828459045) raised to the power of the specified number. |
FLOOR(num) | Largest integer that is less than or equal to the specified number. |
LN(num) | Natural logarithm of the specified number. |
LOG(num, m) | Base-num logarithm of the numerical argument m. |
MOD(num, m) | Remainder of the first numerical argument divided by m. |
PI() | The value of π (3.141592653589793). No arguments accepted. |
POWER(num, m) | Number raised to the power m. |
RANDOM() | Uniformly distributed random number between 0 and 1. |
ROUND(num [,m]) | Number rounded to m decimal places. |
SQRT(num) | Square root of the specified number. |
SELECT value, ABS(value), CEIL(value), EXP(value), FLOOR(value), LN(value), LOG(10, value), MOD(value, 3), PI(), POWER(value, 2), ROUND(value), SQRT(value)
FROM "cpu_busy"
WHERE datetime >= NOW - 1*MINUTE
AND entity = 'nurswgvml007'
| value | abs(value) | ceil(value) | exp(value) | floor(value) | ln(value) | log(10, value) | mod(value, 3) | pi() | power(value, 2) | round(value) | sqrt(value) |
|--------|------------|-------------|----------------|--------------|-----------|----------------|---------------|-------|-----------------|--------------|-------------|
| 19.590 | 19.590 | 20.000 | 321980003.291 | 19.000 | 2.975 | 1.292 | 1.590 | 3.142 | 383.768 | 20.000 | 4.426 |
Trigonometric Functions
| Function | Description |
|---|---|
DEGREES(num) | Convert specified radian value to degrees. 1 rad = 180°/π = 57.2958° |
RADIANS(num) | Convert specified degree value to radians. 1° * π/180° = 0.0174533 rad |
SIN(num) | Sine of the specified angle.num is the angle in radians. |
COS(num) | Cosine of the specified angle.num is the angle in radians. |
TAN(num) | Tangent of the specified angle.num is the angle in radians. |
ASIN(num) | Arcsine sin-1 of the specified sine value. Argument num must be on the interval [-1,1].Out of range arguments return NaN. |
ACOS(num) | Arccosine cos-1 of the specified cosine value. Argument num must be on the interval [-1,1].Out of range arguments return NaN. |
ATAN(num) | Arctangent tan-1 of the specified tangent value. |
SELECT value, DEGREES(value), DEGREES(pi()/2), SIN(RADIANS(45)), RADIANS(180),
SIN(value), COS(value), TAN(value), ASIN(SIN(value)), ACOS(COS(value)), ATAN(value)
FROM "angle"
WHERE datetime < now
| value | degrees(value) | degrees(pi() / 2) | sin(radians(45)) | radians(180) | sin(value) | cos(value) | tan(value) | asin(sin(value)) | acos(cos(value)) | atan(value) |
|-------|----------------|-------------------|------------------|--------------|------------|------------|------------|------------------|------------------|-------------|
| 3.142 | 180.000 | 90.000 | 0.707 | 3.142 | 0.000 | -1.000 | 0.000 | 0.000 | 3.142 | 1.263 |
String Functions
| Function | Description |
|---|---|
UPPER(s) | Converts characters in a specified string to upper case. Example: if entity is abc ⇒ UPPER(entity)=ABC. |
LOWER(s) | Converts characters in a specified string to lower case. Example: if value of tag t1 is ABc ⇒ LOWER(tags.t1)=abc. |
REPLACE(s-1, s-2, s-3) | Replaces all occurrences of s-2 with s-3 in a specified string s-1.If s-2 is not found, the function returns the original string s-1.Example: if entity is abca ⇒ REPLACE(entity,'a','R')=RbcR. |
LENGTH(s) | Number of characters in a specified string. Example: if entity is abc ⇒ LENGTH(entity)=3. |
CONCAT(s-1, s-2 [, s-N] ) | Concatenates multiple strings into one string. NULL and NaN values are concatenated as empty strings.Also accepts numeric values which are converted to strings using #.## pattern.Example: if entity is abc ⇒ CONCAT(entity,'-f-',3.1517)=abc-f-3.15. |
LOCATE(s-1, s-2 [, start]) | Searches for the first string s-1 in the second string s-2.Returns the position at which s-1 is found in s-2, after the optional start position. The first character has a position of 1. The function returns 0 if string s-1 is not found.Example: if entity is abc ⇒ LOCATE('b', entity) is 2. |
SUBSTR(str, start[, length]) | Substring of str starting at start position with maximum length of length. The first character has a position of 1. start position of 0 is processed similarly to position 1.If length is not specified or is 0, the function returns the substring beginning with start position.Example: if entity is abc ⇒ SUBSTR(entity,2)=bc. |
SELECT datetime, UPPER(REPLACE(entity, 'nurswg', '')) AS "entity", value,
SUBSTR(tags.file_system, LOCATE('vg', tags.file_system)) AS fs
FROM "df.disk_used"
WHERE datetime >= NOW - 1*MINUTE
AND LOWER(tags.file_system) LIKE '%root'
ORDER BY datetime
| datetime | entity | value | fs |
|----------------------|--------|-----------|-------------------------|
| 2017-09-30T07:57:28Z | VML006 | 8298304.0 | vg_nurswgvml006-lv_root |
| 2017-09-30T07:57:29Z | VML007 | 8052512.0 | vg_nurswgvml007-lv_root |
Window Functions
LAG
The LAG function provides access to a preceding row at a specified offset from the current position.
LAG(varchar columnName [, integer offset [, defaultValue]])
Example:
LAG(value)
- The default
offsetis1. - If the requested row does not exist, the function returns
NULL, ordefaultValueif specified. - The returned data type is determined similar to the
ISNULLfunction. - If the result set is partitioned with the
ROW_NUMBERclause, the function can access rows only within the same partition as the current row.
SELECT date_format(datetime, 'yyyy') AS "Date",
SUM(value) AS "Current Period",
LAG(SUM(value)) AS "Previous Period",
SUM(value)-LAG(SUM(value)) AS "Change",
round(100*(SUM(value)/LAG(SUM(value))-1),1) AS "Change, %"
FROM "cc.cases-by-primary-type"
WHERE tags.etype = 'OUTAGE'
GROUP BY entity, tags.etype, period(1 year)
| Date | Current Period | Previous Period | Change | Change, % |
|------|----------------|-----------------|--------|-----------|
| 2001 | 654 | null | null | null |
| 2002 | 650 | 654 | -4 | -0.6 |
| 2003 | 590 | 650 | -60 | -9.2 |
The function can be referenced in the WHERE clause to filter rows based on previous row values:
SELECT datetime, text, LAG(text)
FROM "Unit_BatchID"
WHERE entity = 'qz-1211'
AND text = '800' OR LAG(text) = '800'
| datetime | text | lag(text) |
|----------------------|----------|-----------|
| 2017-10-04T01:52:05Z | 700 | null | -- excluded: text is '900' and LAG is null
| 2017-10-04T02:00:34Z | Inactive | 700 | -- excluded: text is 'Inactive' and LAG = '700'
| 2017-10-04T02:01:20Z | 800 | Inactive |
| 2017-10-04T02:03:05Z | Inactive | 800 |
| 2017-10-04T02:03:10Z | 800 | Inactive |
| 2017-10-04T02:07:05Z | Inactive | 800 |
| 2017-10-04T02:09:09Z | 900 | Inactive | -- excluded: text is '900' and LAG = 'Inactive'
| 2017-10-04T02:12:30Z | Inactive | 900 | -- excluded: text is 'Inactive' and LAG = '900'
The LAG function in the SELECT expression is applied to the filtered result set, after some rows have been excluded by the LAG function as part of the WHERE clause. Therefore, LAG() in SELECT and LAG() in WHERE clauses can return different values.
SELECT datetime, LAG(value), value, LEAD(value)
FROM "mpstat.cpu_busy"
WHERE entity = 'nurswgvml007'
AND datetime BETWEEN '2017-04-02T14:19:15Z' AND '2017-04-02T14:21:15Z'
--AND value > LAG(value) AND value < LEAD(value)
- Rows before filtering
| datetime | lag(value) | value | lead(value) |
|----------------------|------------|-------|-------------|
| 2017-04-02T14:19:17Z | null | 25.5 | 6.1 |
| 2017-04-02T14:19:33Z | 25.5 | 6.1 | 13.3 |
| 2017-04-02T14:19:49Z | 6.1 | 13.3 | 55.0 | +
| 2017-04-02T14:20:05Z | 13.3 | 55.0 | 6.1 |
| 2017-04-02T14:20:21Z | 55.0 | 6.1 | 7.0 |
| 2017-04-02T14:20:37Z | 6.1 | 7.0 | 8.0 | +
| 2017-04-02T14:20:53Z | 7.0 | 8.0 | 20.2 | +
| 2017-04-02T14:21:09Z | 8.0 | 20.2 | null |
- Rows after filtering
| datetime | lag(value) | value | lead(value) |
|----------------------|------------|-------|-------------|
| 2017-04-02T14:19:49Z | null | 13.3 | 7.0 | LAG and LEAD in SELECT show different values
| 2017-04-02T14:20:37Z | 13.3 | 7.0 | 8.0 |
| 2017-04-02T14:20:53Z | 7.0 | 8.0 | null |
LEAD
The LEAD function provides access to a following row at a specified offset from the current position.
LEAD(varchar columnName [, integer offset [, defaultValue]])
Example:
LEAD(value)
- The default
offsetis1. - If the requested row does not exist, the function returns
NULL, ordefaultValueif specified. - The returned data type is determined similar to the
ISNULLfunction. - If the result set is partitioned with the
ROW_NUMBERclause, the function can access rows only within the same partition as the current row.
The LEAD function operates similarly to the LAG function except that it searches for subsequent rows as opposed to previous rows.
FIRST_VALUE
The FIRST_VALUE is an analytical function that returns the first row within the partition.
FIRST_VALUE(varchar columnName)
Example:
FIRST_VALUE(value)
The function operates similar to LAG(expr, offset) where offset is the number of rows minus 1.
Lookup Functions
METRICS
METRICS(varchar entityName [, varchar entityName2])
The METRICS function is supported in queries to the atsd_series, atsd_metric, atsd_entity tables and retrieves all metrics collected by the specified entity or multiple entities.
The list of metrics can be additionally filtered in the WHERE clause.
SELECT metric, datetime, value
FROM atsd_series
WHERE metric IN metrics('nurswgvml007')
-- WHERE metric IN metrics('entity-1', 'entity-2')
AND metric LIKE 'mpstat.cpu%'
-- AND metric NOT LIKE 'df.%'
AND datetime >= CURRENT_HOUR
ORDER BY datetime
LIMIT 10
| metric | datetime | value |
|-------------------|----------------------|-------|
| mpstat.cpu_system | 2017-04-06T16:00:02Z | 8.3 |
| mpstat.cpu_nice | 2017-04-06T16:00:02Z | 0.0 |
| mpstat.cpu_steal | 2017-04-06T16:00:02Z | 0.0 |
| mpstat.cpu_idle | 2017-04-06T16:00:02Z | 70.7 |
| mpstat.cpu_user | 2017-04-06T16:00:02Z | 17.9 |
| mpstat.cpu_iowait | 2017-04-06T16:00:02Z | 2.0 |
| mpstat.cpu_busy | 2017-04-06T16:00:02Z | 29.3 |
| mpstat.cpu_system | 2017-04-06T16:00:18Z | 4.6 |
| mpstat.cpu_nice | 2017-04-06T16:00:18Z | 0.1 |
| mpstat.cpu_steal | 2017-04-06T16:00:18Z | 0.0 |
COLLECTION
The COLLECTION function retrieves the list of strings for the specified Named Collection. The list can be checked for matching using IN and NOT IN operators.
SELECT * FROM "df.disk_used"
WHERE datetime > now - 1 * DAY
AND tags.file_system NOT IN collection('fs_ignore')
ORDER BY datetime
LOOKUP
The LOOKUP function translates the key into a corresponding value using the specified replacement table. The function returns a string if the replacement table exists and the key is found, and returns NULL otherwise. The key comparison is case-sensitive.
LOOKUP(varchar replacementTable, varchar key)
If the key is numeric, such as in the LOOKUP('table-1', value) case, the number is formatted with #.## pattern to remove fractional .0 parts from integer values stored as decimals.
- Dictionary
The primary purpose of a replacement table is to act as a dictionary for decoding series tags/values.
SELECT datetime, entity, ISNULL(LOOKUP('tcp-status-codes', value), value)
FROM "docker.tcp-connect-status"
WHERE datetime >= NOW - 5*MINUTE
AND LOOKUP('tcp-status-codes', value) NOT LIKE '%success%'
If the searched key is a number provided by the value column or an arithmetic expression, such number is formatted into a string using the #.## pattern.
1.0 -> 1
1.20 -> 1.2
1.23 -> 1.23
1.2345 -> 1.23
For DIGSTRING(integer code)
SELECT datetime, entity, value, LOOKUP('pi-system', value)
FROM atsd_series
WHERE metric = 'digtag-test'
AND datetime >= PREVIOUS_HOUR
- Fact Table
In addition, replacement tables can be used as fact tables, storing numeric data without a time dimension.
Replacement table 'us-region':
1=New-England
2=Middle-Atlantic
3=East-North-Central
...
Replacement table 'city-size':
Akron,OH=197542
Albany,NY=98469
Albuquerque,NM=559121
...
SELECT date_format(time, 'yyyy-MM-dd') AS "date", value, tags.city, tags.state,
LOOKUP('us-region', tags.region) AS "region",
LOOKUP('city-size', CONCAT(tags.city, ',', tags.state)) AS "population",
value/CAST(LOOKUP('city-size', CONCAT(tags.city, ',', tags.state)) AS Number)*1000 AS "cases_per_pop"
FROM "cdc.pneumonia_cases"
WHERE tags.city = 'Boston'
ORDER BY datetime DESC
LIMIT 1
| date | value | tags.city | tags.state | region | population | cases_per_pop |
|------------|-------|-----------|------------|-------------|------------|---------------|
| 2017-10-01 | 131.0 | Boston | MA | New-England | 667137 | 0.2 |
IS_ENTITY_IN_GROUP
The IS_ENTITY_IN_GROUP function returns true if arg1 matches one of the entity names in the specified entity group.
IS_ENTITY_IN_GROUP(varchar entity, varchar groupName)
SELECT entity, AVG(value)
FROM "mpstat.cpu_busy"
WHERE datetime > current_hour
AND is_entity_in_group(REPLACE(entity, 'nur', ''), 'nur-hbase')
GROUP BY entity
ENTITY_TAG
The function returns tag value for the specified entity name and tag name.
ENTITY_TAG(varchar entity, varchar tagName)
SELECT value, entity_tag('nurswgvml007', 'site')
PROPERTY
The function retrieves the first matching property value for the specified entity and property search expression. The function operates similar to the property() function in the rule engine.
property(string entity, string expression [, long time | string datetime [, boolean merge]]) string
SELECT entity, property(entity, 'location::site') AS site
FROM "mpstat.cpu_busy"
WHERE time > now - 5*minute
Other Functions
ISNULL
The ISNULL function returns arg2 if arg1 is NULL or NaN (Not-A-Number) in the case of numeric expressions.
ISNULL(arg1, arg2)
The function accepts arguments with different data types, for example numbers and strings ISNULL(value, text).
If the data types are different, the database classifies the column as
JAVA_OBJECTto the JDBC driver.
COALESCE
The COALESCE function returns the first argument that is not NULL and not NaN (Not-A-Number) in case of numeric expressions.
COALESCE(arg1, arg2, ..., argN)
At least two arguments must be specified. If all arguments evaluate to NULL or NaN, the function returns NULL.
The function accepts arguments with different data types, for example numbers and strings COALESCE(value, text, 'Unknown').
If the data types are different, the database classifies the column as
JAVA_OBJECTto the JDBC driver.
CAST
The CAST function transforms a string into a number, or a number into a string or timestamp.
CAST(inputString AS NUMBER)
CAST(inputNumber AS STRING)
CAST(inputNumber AS TIMESTAMP)
The returned number can be used in arithmetic expressions, whereas the returned string can be passed as an argument into string functions.
SELECT datetime, value, entity, tags,
value/CAST(LOOKUP('disk-size', CONCAT(entity, ',', tags.file_system, ',', tags.mount_point)) AS number) AS "pct_used"
FROM "disk.stats.used"
WHERE datetime >= CURRENT_HOUR
The result of CAST(inputNumber AS string) is formatted with the #.## pattern to remove the fractional part from integer values stored as decimals. The numbers are rounded to the nearest 0.01.
CAST of NaN to string returns NULL.
Options
The OPTION clause provides hints to the database optimizer on how to execute the given query most efficiently. Unlike the WITH clause, the option does not change the results of the query.
The query can contain multiple OPTION clauses specified at the end of the statement.
ROW_MEMORY_THRESHOLD Option
The database can choose to process rows using the local file system as opposed to memory if the query includes one of the following clauses:
JOINORDER BYGROUP BYWITH INTERPOLATEWITH ROW_NUMBER
The OPTION (ROW_MEMORY_THRESHOLD {n}) forces the database to perform processing in memory if the number of rows is within the specified threshold {n}.
Example:
SELECT entity, datetime, AVG(value), tags
FROM "df.disk_used"
WHERE datetime >= CURRENT_DAY
GROUP BY entity, tags, PERIOD(2 HOUR)
ORDER BY entity, tags.file_system, datetime
OPTION (ROW_MEMORY_THRESHOLD 10000)
If {n} is zero or negative, the results are processed using the local file system.
This clause overrides the conditional allocation of shared memory established with the Settings > Server Properties:sql.tmp.storage.max_rows_in_memory setting which is set to 50*1024 rows by default.
The sql.tmp.storage.max_rows_in_memory limit is shared by concurrently executing queries. If a query selects more rows than remain in the shared memory, the query results are processed using the local file system which can increase response time during heavy read activity.
The row count threshold is applied to the number of rows selected from the underlying table, and not the number of rows returned to the client.
Example. Temporary Table Grouping and In-Memory Ordering
Scheduler
SQL statements can be executed interactively via the SQL Console as well as on a schedule.
Scheduled execution allows for generated report files to be distributed to email subscribers or stored on a local file system.
The data returned by SQL statements can be exported in the following formats:
| Endpoint | Formats |
|---|---|
| API | CSV, JSON |
| Web Console | CSV, JSON, HTML |
| Scheduler | CSV, JSON, Excel |
The Store option allows for query results to be stored back in the database as new derived series.
SQL Compatibility
While the differences between SQL dialect implemented in ATSD and SQL specification standards are numerous, the following exceptions to DML syntax are worth mentioning:
LEFT OUTER JOINandRIGHT OUTER JOINqueries are not supported.- Subqueries are supported only by the
BETWEENoperator applied to thetimeanddatetimecolumns. UNION,EXCEPTandINTERSECToperators are not supported.- In case of division by zero, the database returns
NaNaccording to the IEEE 754-2008 standard instead of terminating processing with a computational error. - The
WITHoperator is supported only in the following clauses:WITH ROW_NUMBER,WITH INTERPOLATE,WITH LAST_TIME,WITH TIMEZONE.